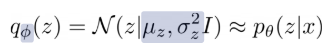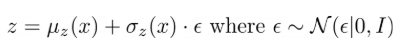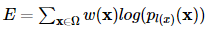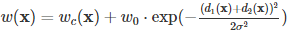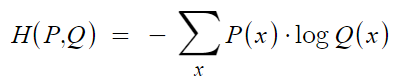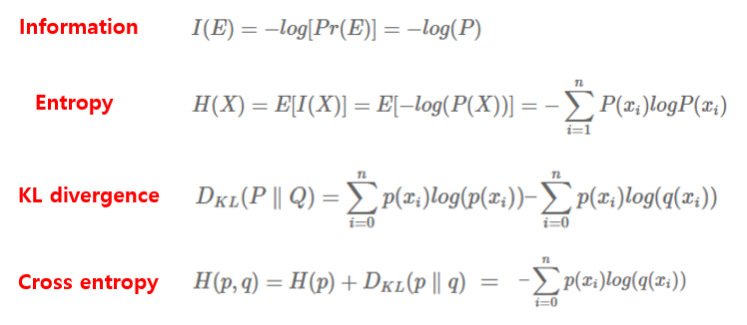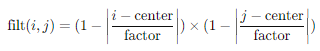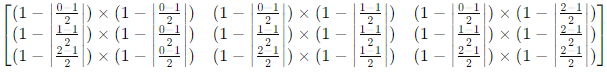Data distribution을 알면 p(x)를 기반으로 새로운 samples를 만들거나 새로운 데이터 ˜x가 기존에 관측된 data와 유사한지 판단할 수 있다. 따라서 우리는 model을 통해 data distribution을 approximate하는 것이 목표이고 data distribution을 approximate한다는 것은 observed data x에 대해 likelihood p(x)를 maximize하는 것과 같다.(model에서도 관찰된 데이터가 '관찰'될 확률을 높인다는 것)
보통 많은 확률을 곱하는 것은 매우 작은 값을 야기하기 때문에 log를 씌워 곱을 합으로 전환한다.
하지만 우리의 data는 보통 high-dimensional하기 때문에 그 분포는 매우 complex하다. 이를 해결하기 위해 indirect approach인 laten variable methods를 사용한다.
이 접근방법은 우리의 관측된 x가 관측되지 않는 미지의 변수인 z로부터 생성됬다고 가정하는 것이다. 보통 이 미지의 변수를 latent variable 혹은 hidden variable인데 low-dimensional임이 자연스럽다.(high-dimensional하면 도입할 이유가 없다!)
이제 우리는 modeling하려던 p(x) 대신 p(x,z)를 예측하면 되고 이 p(x,z)는 p(z)와 p(x|z) 두개의 곱으로 이루어진다. 즉,
여기서의 likilihood는 우리가 도입한 변수인 z와 x 사이간의 likelihood이고 p(z)는 우리가 가정한, 추측한 확률이므로 prior probability로 해석한다.
이렇게 latent variable을 도입한 예시로 gaussian을 활용한 방법이 있다.
Data distribution이 gaussians의 mixtue N개로 되어있다고 가정하여 data가 그 중 하나로부터 생성되었다고 해석한다.
오른쪽 위 식의 h는 잘못되었고 z가 맞다.
이 관점의 특징은 z를 discrete variabe로 본다는 것이다. 따라서 z의 분포는 각 값을 가질 확률로 표현되는 discrete distribution이고 각 data는 자신이 generate된 gaussian의 index인 component index를 갖는다.
data의 분포(회색)이 각각의 gaussians(주황색, 초록색, 파란색)으로 이루어져있다.
이 아이디어를 확장한 latent variable model로 non-linear lattent variable model이 있는데 이 모델은 latent variable z가 countinuous variable이고 nomarl prior로 부터 sampling되었다고 가정한다. 즉,
여기서 p(x❘z)에서 mean에 해당하는 부분만 f(z)로 나타냈는데 각 분포의 분산도 예측하게 할 수는 있다.
그런데 Conditional probability의 mean을 예측하는 f(z)는 신경망 같은 함수인 non-linear function 이기 때문에 위 적분이 불가능하다.(선형이면 가능) 그러니까 지금 생긴 문제를 정리해보면 우리는 p(x)의 likelihood를 maximize해야 하는데 직접 접근하는 것이 어려워 latent variable을 도입했지만 그럼에도 불구하고 closed form이 존재하지 않는 상황인 것이다.
따라서 이를 해결하기 이해 lower bound를 도입해 proxy objectibve(대리 목적함수)를 사용한다.
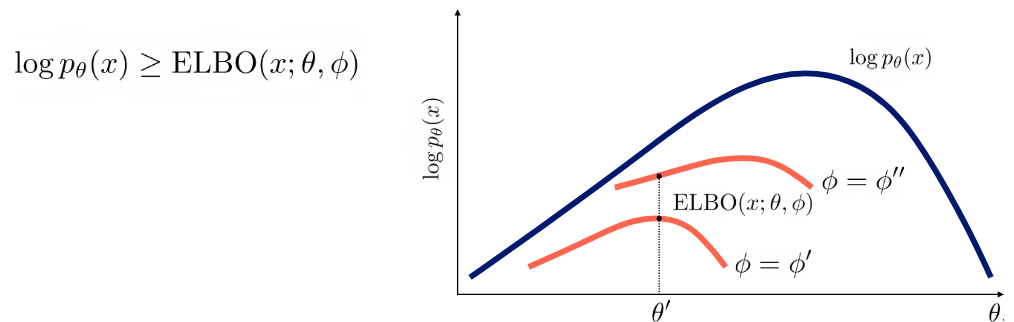
1 . ELBO: Evidence Lower Bound
ELBO에서 evidence는 observed data의 log-likelihood를 의미한다. 즉, ELBO는 위에서 말한 proxu objective인것.
이제 ELBO를 어떻게 해석할지 알아보기 위해 Jensen's Inequality로 식을 전개해볼 것인데 먼저 Jensen's Inequality는 다음과 같다.
간단하게 말하면 convex function에서 함수값의 평균이 평균의 함수값보다 크다는 것
log function은 concave하기 때문에 평균의 함수값이 함수값의 평균보다 큰 성질을 이용할 것이다. 그럼,
이렇게 식이 전개되고
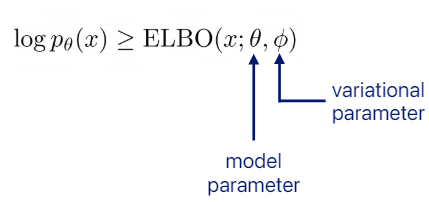
ELBO는 위와 같이 쓸 수 있다. 여기서 세타는 p를 결정하는 parameters이고 파이는 q를 결정하는 파라미터이다.
2. Variational Inference(VI)
그 다음은 ELBO를 최대화 하는 과정을 배울 것인데 처음 배울 때 매우 신기한 아이디어인 VI에 대해 알아보자. ELBO를 이렇게 전개할 수도 있다.
x와 z의 joint distribution에 z에 대한 posterior를 도입한 것인데(이게 참 웃긴게 우리는 z가 x를 만들었다고 가정했지만 여기서의 확률은 given x, z의 분포에서 얻은 확률이다.) ELBO가 원래 우리가 구하려던 evidence에 z의 분포와 p(z|x)의 KL-divergene를 뺀 것이라는 것이다. 즉, tight한 바운드는 두 분포 z를 예측한 분포(q), z의 posterior이 같았을 때이다.
그럼 우리는 ELBO를 어떻게 maximize할까? 우리는 E-M Method(Expectation-Maximization Method,velog에 올라와있는데 추후 가져올 예정..)를 통해 세타와 파이를 번갈아가면서 최적화 해 evidence의 max에 가까워질 수 있다. 즉, 간접적으로 intractable(적분 불가능한) evidence를 optimize하는 것이다.
bound가 원 object에 가까워지는 걸 tight해진다고 표현한다.
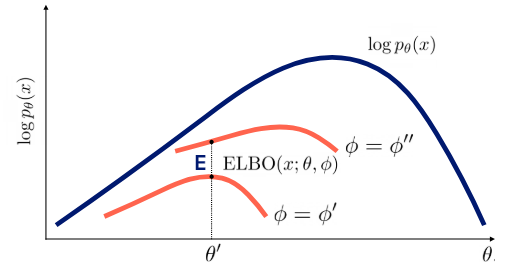
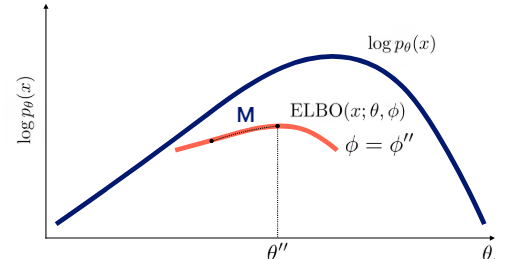
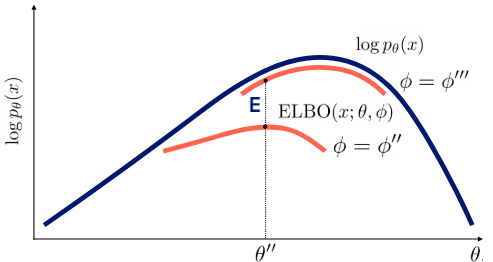
위에서 말한 expectation과 maximization 과정은 각각 tight한 bound를 만드는(파이를 update), bound를 개선하는(세타를 update)하는 것인데 그림으로 나타내면 다음과 같다.
물론 파이를 update한다고 완전하게 tight한 bound를 만들 순 없다.(그게 가능하면 posterior을 완벽하게 구현해낸 것)
하지만 여기까지 글을 읽을 보면서 이상한 점이 느껴져야 하는데 z의 posterior이 과연 뭐냐는 것이고 계산할 수 있냐는 것이냐이다.
식을 보면 posterior를 알기 위해선 p(x)를 알아야한다.(p(x)가 어려워서 z도입했더니 p(x)를 계산해야 하는 웃픈 상황) p(x)는 매우 복잡한 분포여서 이 식 역시 계산할 수 없으므로 E-M method를 사용하지 못한다.
그래서 사용하는 방법이 variational approximation인데 이 방법은 간단한 parametric distribution으로 근사하는 방법으로 z의 posterior를 가우시안 분포로 근사한다.(q를 구하는 parameters인 파이는 variational parameters라 하고 복잡한 함수를 근사하여 추론하는 것을 variational inference라 한다. 그리고 variational parameters는 당연히 x에 딸라 달라지므로 x에 대한 함수로 볼 수 있다.)
물론 이 발상이 항상 타당한 것은 아니다. 아래 그림에서는 꽤나 괜찮은 근사를 하지만
이 그림에선 매우 poor하다.
다시 그동안 했던 것들을 되돌아보면
Evidence를 maximize하려던 목표는 ELBO을 maximize하는 것으로 바뀌었고 이는 q(z)와 p(z|x)의 차이를 최소화하는 과정이 필요했으나 불가능하여 variational approximation을 사용한다. 마치
를 하는 것과 같아진 것.
3. Variational Auto-Encoder(VAE)
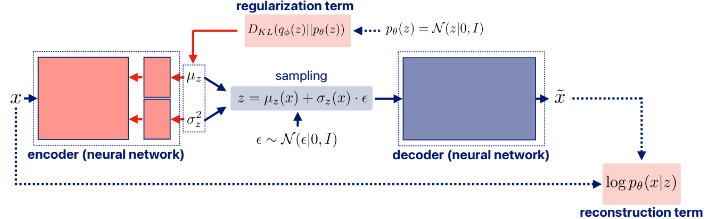
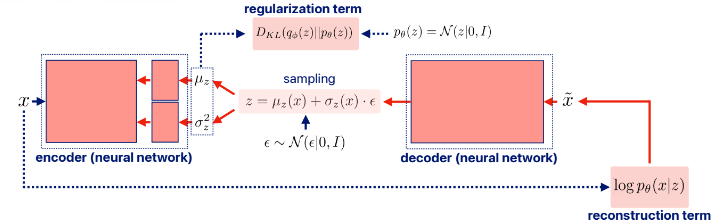
이번엔 VI를 응용한 신경망인 VAE에 대해 알아보자. VAE는 x를 latent variable z로 encoding하고 이를 다시 decoding하여 x와 유사한 x틸다를 생성하는 것이다. z에 대한 posterior이 아닌 prior를 도입해보자.
여기서 왼쪽 term은 reconstruction term이라 하는데
근사된 z(q(z)의 확률 분포를 갖는 z)에서 x가 잘 re-generate되는지 확인하는 term이다. 값은 당연히 크면 클수록 잘 근사한 것이다.
오른쪽 term은 regularization term인데
근사한 z의 분포가 실제 z의 분포(prior)과 유사해는지 확인하는 term이다. 값이 크면 차이가 큼을 의미하므로 -가 붙는다.
일반적으로 VAE에서 z의 prior는 N(0,1)로 가정한다.
Regularization term을 보면 (생략되었지만 두 분포 모두 given x에서 얻어졌다.) 따라서 variational parameters 역시 VI와 마찬가지로 x에 대한 함수이다. VI에선 언급하지 않았지만 이 부분이 문제가 되는데 그럼 모든 x에 대해서 파이를 계산해야 하는 문제가 생겨 scalable하지 않다.(scalable하다는 것은 많은 양의 x에서도 합리적인 계산이 가능해 확정가능함을 의미한다.)
뮤와 시그마를 모든 x에 대해 추론해야 한다.
따라서 VAE에서 도입한 것이 encoder architecture인데 이 구조로 amortized inference가 가능하다.
뭔 소리냐? x를 입력하면 뮤와 시그마를 출력하는 신경망을 만드는 것. 이 신경망 하나를 학습시키면 각 파라미터를 모두 학습시키는 것보다 훨씬 간단해진다.(amortized는 '공통으로, 한꺼번에'를 의미한다.)
이렇게 만든 q(z|x)에서 z를 sampling하고 decoder를 통해 x 틸다를 만들어 낸다.
그럼 실제로 reconstruction term을 어떻게 계산하는지 알아보자.
decoder 역시 encoder와 비슷하게 p(x❘z)를 normal distribution으로 modeling하고 x 틸다를 sampling한다. 단, encoder와 다르게 분산을 1로 가정하기도 한다.
VAE 역시 신경망이다 보니 differentiable이 필수이다. 하지만 sampling process는 일반적으로 non-differentiable이다. 따라서 우린 reparameterization trick을 통해 이 과정을 미분가능하게 할 것인데 z를
로 sampling하고 gradient를 계산하는 것이다. z의 prior이 N(0,1)으로 unbiased하고 minibatch size가 클 때 이렇게 one sample로 gradient를 계산하여도 동일한 효과를 내는 것은 수학적으로 밝혀져있다.(이부분은... 납득!)
이후 decoder 과정에서 x 틸다를 N(x|x*, I)에서 sampling하는데(시그마를 1로 가정) 이 때
가 성립한다.(x_{rec} = x 틸다)
왜냐하면 가우시안 분포가
이렇게 생겼는데 log를 씌우면
이고 앞 항은 constant여서
이다. 즉, 의미를 분석하면 reconstruction term은 x와 x 틸다 사이의 유클리드 거리의 제곱이 최소화되도록 학습하는 것이다.
이번엔 regularization term을 살펴보자.
p(z)는 일반적으로 N(0,1)로 가정하고 q(z)는 z의 posterior 인데 이 역시 Gaussian distribution이므로 위 식은 closed form이 존재해 생각보다 쉽게 계산된다.
즉, sampling을 포함한 전체 process를 보면
가 된다. 이제 각 term이 어느 층과 연결되는지까지 표현하면
이렇게 되고 역전파를 나타내면
와
이다. 결론적으로 우리는 latent variable z를 통해 새로운 것을 'generation' 할 수 있게 되었다.
+
decoder 역시 encoder와 비슷하게 p(x❘z)를 normal distribution으로 modeling하고 x 틸다를 sampling한다. 단, encoder와 다르게 분산을 1로 가정하기도 한다.
이 주석을 봤을 때 의문이 들어야 하는 것이 'x 틸다를 sampling한다.'는 표현이다. 그럼,
이 backporpagation에서 x 틸다는 sampling process를 거치기 때문에 미분이 가능한지 의구심을 들게 만든다.
결론부터 말하면 둘다 맞다.
우선 미분이 가능한 이유는 deocder는 주어진 z에 대해 하나의 결정적인 출력을 만든다. 즉, 주어진 z에 대해 항상 동일한 x 틸다를 생성하는 것이다.(x 틸다 = g(z)) 그럼, sampling 했다고 표현할 수 있는지 생각이 들 수 있는데 x가 잠재 변수 z로부터 생성될 때 가우시안 분포로부터 생성된다고 가정했기 때문에 하나의 sample을 추출한 것으로 해석할 수 있다. 당연히 정규 분포에서 가장 가능성이 높은 평균을 sample하는 것이 자연스럽기 때문에 이 x틸다는 z로부터 출력한 p(x|z_ 분포의 평균이고 이를 통해 reconstruction term을 계산한다.
정리하면 z를 통해 x가 바로 결정되고 x는 p(x|z)에서 하나 sampling 된 것으로 볼 수 있다.
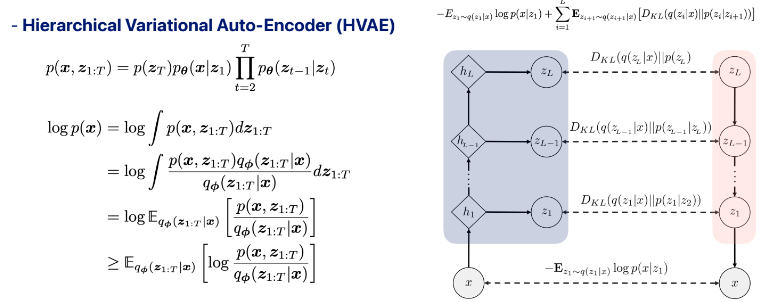
4. Hierachical Variational Auto-Encoder(HVAE)
VAE에서 latent variable이 여러 개로 확장되고 각각이 depencency가 존재하는 모델이 HVAE이다. 이는 diffusion의 기반이 되니 다음 포스트에서 또 언급하겠다.
5. Recurrent VAE
VAE를 확장한 또다른 구조로 recurrent VAE가 있다. Hidden variables 사이에 recurrence가 존재하는 것이 특징이다.
6. Problems with VAE
1. inefficient to evaluate / measure the likelihood of observed data
: 애초에 위 과정이 모두 이루어진 것이 p(x|z)p(z)dz가 적분이 되지 않아 이런 먼길을 돌아온 것이다. 적분을 학술이는 방법이 있긴 하지만(MCMC(Markov Chain Monte Carlo) 방법은 복잡한 확률 분포에서 샘플링하여 적분 문제를 해결하는 강력한 수치적 방법) 계산 과정이 매우 많아 비효율적이다.
2. not perfect samples from the distribution
: 1번 때문에 간단한 함수로 근사하는 variational inference를 하지만 '간단한' 함수이기 대문에 생성하는데 완벽하지 않다. 즉 normal distribution으로 복잡한 분포는 근사하기에는 충분하지 않다. 실제로 생성해보면 over smoothing한 x 틸다가 아래처럼 생긴다.
3. posterior collapse with strong decoder
: 만약 decoder가 너무 강하면(capacity가 크다면) 잠재변수 z를 무시하고 그냥 x로부터 x틸다를 구성해버린다. Encoder를 사용하지 않지만 마치 학습되는 것처럼 보이기 대문에 모델의 표현력이 개선되지 않는다.
7. 마무리
이렇게 저번 기말 범위 중 하나였던 VAE에 대한 내용을 마치고 다음 포스트는 HVAE에 제약을 더한 diffusion에 대해 올려보겠다. (지금부터 해야 되긴해..)
전체 데이터셋은 크게 3개로 나눠있는데 하나의 part만 가져와도 256*256의 이미지가 2656개가 있어서 충분하다고 판단해(사실 충분한단 것은 gpu memory의 한계를 의미하는 것과 같다.) part 1만 사용하였다. Author Notes의 README를 읽어보면 19개의 tissue types의 데이터로 이루어져있으며 각각은 0: Neoplastic cells, 1: Inflammatory, 2: Connective/Soft tissue cells, 3: Dead Cells, 4: Epithelial, 6: Background 이렇게 마스킹 되어있다. 용어를 하나하나 살펴보면
Neoplastic cells : 종양을 형성하는 세포 Inflammatory : 염증성 Connective/Soft tissue cells: 결합조직 및 연조직으로 신체의 구조와 지지 기능을 담당하는 세포들 Dead Cells: 죽은 세포, 더 이상 기능하지 않는 세포 Epithelial: 상피 세포, 신체의 표면과 내부 장기를 덮고 있는 세포
인데 오랜만에 생물 공부를 하는 느낌이다. 그리고 추가적으로 데이터 형식을 살펴보면 특이하게 images와 masks가 images.npy, masks.npy로 되어 있다는 것이다. (npy 파일은 NumPy 라이브러리에서 사용하는 파일 형식으로, 다차원 배열 데이터를 효울적으로 저장하고 로드하는데 사용된다.)
(코드의 mmap_mode 매개변수는 매모리 맵핑을 사용하여 대용량 배열 데이터를 디스크에서 직접 읽는 방식을 지정하는데 사용한다. 이 값을 기본값으로하게 되면 매모리 맵핑을 사용하지 않아 파일 전체가 메모리에 로드되는데 파일 양이 커서 local의 경우 과부화가 걸린다. 따라서 읽기 전용 모드로 파일을 메모리에 매핑하여 데이터의 일부만 로드하고 필요한 부분만 읽게 하였다. 즉, 메모리 사용량을 줄이고 입출력 성능을 향상시키기 위해 하는 것!)
(2656, 256, 256, 3)
(2656, 256, 256, 6)
출력해보면 masks의 채널이 왜 6인지는 위에 데이터셋을 보면 알 수 있을 것이다. 일전의 FCN에서 했던 cloth segmentation의 경우 semantic segmentation이기 때문에 2차원 mask에서 각 pixel의 값에 class의 number를 매핑하면 충분하였다. 하지만 이번 task는 instance segmentation을 해야하기 때문에 3차원 mask에 각 채널이 하나의 class를 의미하고 각 class에 해당하는 instance를 숫자로 매핑하게 되었다. Semantic segmentation과 instance segmentation이 무엇이지 까먹었다면 이 곳으로
항상 해왔듯이 Dataset class인 NumpySegDataset class를 정의하고 __init__,. __len__함수와 __getitem__ 함수를 정의하였다. 다만 저번 미니 프로젝트와는 다른 점은 __init__ 함수를 만들 때 numpy 배열이기 때문에 np.load와 mmap_mode = 'r'이라는 점이다.
dataset을 로딩해줄 때 8:2의 비율로 train과 validation을 구분하였다. (batch size가 4로 매우 작은 편인데 batch size를 좀만 늘려도 OOM(Out of Memory) 문제가 발생하여서 batch size와 epoch를 모두 줄이게 되었다.)
다음과 같은데 최대한 논문에서 말하는 구조를 따라하기 위해 padding을 0으로 하고 croppping하는 과정을 넣었는데 참고한 사이트에선 구현을 용이하기 위해 padding을 사용하였다. 그리고 논문에서 segmentation이 용이하게 되기 위해서는 max pooling을 하는 input의 size가 짝수여야 했는데 이미 이미지의 크기가 256*256으로 제한되어 있어서 이를 늘리거나 줄이지는 않고 홀수 일때만 padding을 추가하는 방식으로 구현하였다. torch.summary를 사용해 출력해보면 다음과 같다.
model = UNet().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
일반적인 loss fucntion을 사용하는 것이 아닌 각 pixel에 weight를 부여하고 softmax함수와 cross entropy loss를 결합한 loss(논문에 잘 소개되어있다.)를 사용해보기 위해 함수들을 정의해보았다.
defcustom_loss(outputs, labels, weights):# softmax 계산
softmax_outputs = F.softmax(outputs, dim=1)
# CPU로 이동
labels = labels.cpu()
weights = weights.cpu()
softmax_outputs = softmax_outputs.cpu()
# 0이 아닌 위치를 찾기 위한 마스크 생성
non_zero_mask = labels != 0# 마스크를 사용하여 필요한 값 선택 및 계산
selected_weights = weights.unsqueeze(1).expand_as(labels)[non_zero_mask]
selected_softmax_outputs = softmax_outputs[non_zero_mask]
# 손실 계산
running_loss = (-1) * selected_weights * torch.log(selected_softmax_outputs)
running_loss = running_loss.sum()
running_loss /= labels.shape[0] * labels.shape[2] * labels.shape[3]
return running_loss.to(outputs.device)
먼저 outputs에서 softmax를 적용하고(채널이 class별 출력을 위하니 dim=1로 softmax를 계산한다.) labels에서 0이 아닌 위치를 나타내는 non_zero_mask를 정의하였다. weights의 차원은 (batch_size, height, width)이고 non_zero_mask의 차원은 (batch_size, num_classes, height, width)에서 selected_weights를 구하기 위해선 weights에서 두번째 차원을 추가하고 labels의 num_classes만큼 복사한다음 선택을 한다. 그렇게 계산한 selected_weights의 차원은 non_zero의 갯수가 N이라 하면 (N,)이다. 그리고 필는 loss function을 최소화하기 위해 -1을 붙였고 pixel-wise loss때문에 평균을 내기 위해 batch_size와 height, width로 나누어줬다. 그럼 weight는 어떻게 계산할까? 논문에서는
이렇게 class의 frequency를 반영한 1차 weight에 세포와의 거리를 반영하는 추가적인 weight로 계산하였는데 구현이 엄청 어려운 것이지만 시간이 매우 오래 걸릴 것이라 판단하여 비슷한 아이디어로 정의하였다.
import torch
deffind_others(labels, i, j, k, b, d):
left = max(i - d, 0)
right = min(i + d, 255) # 256이 아니라 255까지
up = max(j - d, 0)
down = min(j + d, 255) # 256이 아니라 255까지
instance = labels[b, k, i, j]
region = labels[b, k, left:right+1, up:down+1]
other_classes = (region == 0).sum().item()
other_instances = ((region != 0) & (region != instance)).sum().item()
return other_classes, other_instances
defcalculate_weights(masks):
device = masks.device
batch_size, num_classes, height, width = masks.shape
weights = torch.zeros((batch_size, height, width), device=device)
non_zero_counts = (masks != 0).sum(dim=(2, 3))
for b inrange(batch_size):
non_zero_ratio = non_zero_counts[b].float() / non_zero_counts[b].sum(dim=0, keepdim=True).float()
exp_non_zero_ratio = torch.exp(-non_zero_ratio)
for k inrange(num_classes):
mask_k = masks[b, k]
non_zero_mask = mask_k != 0
weights[b][non_zero_mask] = exp_non_zero_ratio[k]
for i inrange(2, height, 5):
for j inrange(2, width, 5):
if non_zero_mask[i, j]:
other_classes, other_instances = find_others(masks, i, j, k, b, 2)
weights[b, i-2:i+3, j-2:j+3] *= (1.02)**other_classes
weights[b, i-2:i+3, j-2:j+3] *= (1.05)**other_instances
return weights
기본적인 아이디어는 먼저 class의 frequency의 비율에 exp(-x)를 적용하고 해당 pixel을 가운데로 하는 25개의 pixel에 같은 class지만 다른 instance인 pixel의 개수(a)와 다른 class인 pxiel의 개수(b)에 따라 가중치를 각각 1.05**(a), 1.02**(b) 배 해주는 방식이다. 총 2656개의 데이터의 256*256 pixels는 1억개가 넘어서(174,063,616) 다섯 pixels씩 넘어가면서 계산하도록 설계하였다. matplotlib의 pyplot을 사용하여 하나의 weight를 시각해보면 다음과 같다.
경계에서, 특히 다른 instance의 경계에서 가장 높은 weight를 갖도록 설계된 것을 알 수있다.
5. Train & Validation
num_epochs = 50# Number of epochs
batch_size = 4
val_idx_start = len(train_loader.dataset)
for epoch inrange(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}')
# Each epoch has a training and validation phasefor phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
dataloader = train_loader
else:
model.eval() # Set model to evaluate mode
dataloader = val_loader
running_loss = 0.0# Iterate over data with tqdm for the progress bar
progress_bar = tqdm(enumerate(dataloader), total=len(dataloader), desc=f"{phase.capitalize()} Phase")
for batch_idx, (inputs, labels) in progress_bar:
inputs, labels = inputs.to(device), labels.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forwardwith torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
if phase == 'train':
batch_weights = weights[batch_idx * batch_size : (batch_idx + 1) * batch_size]
else:
batch_weights = weights[val_idx_start + batch_idx * batch_size : val_idx_start + (batch_idx + 1) * batch_size]
loss = custom_loss(outputs, labels, batch_weights)
if phase == 'train':
loss.backward()
optimizer.step()
# Statistics
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(dataloader.dataset)
# Update the progress bar with the current loss value
progress_bar.set_postfix({'loss': f'{loss.item():.4f}'})
if phase == 'val':
print(f'{phase.capitalize()} Loss: {epoch_loss:.4f}')
print()
GPU 메모리와 사용량의 한계로 epoch를 50으로 설정하였고 위에서 계산한 weight를 batch에 맞게 가져오도록 설계하였다. 훈련은 총 3시간 정도 걸렸다.
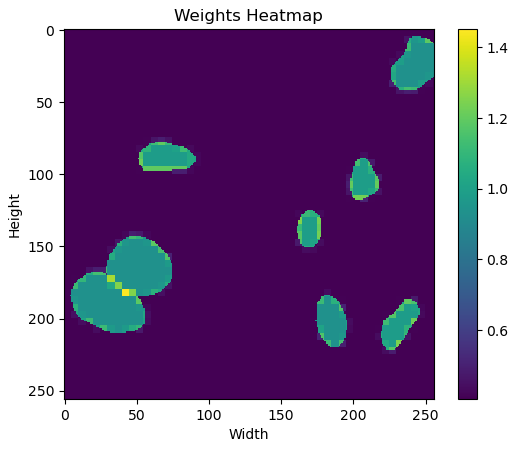
결과를 시각화해보면
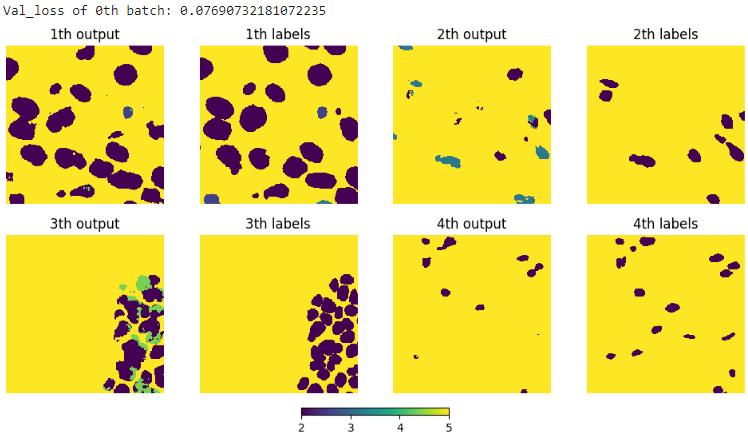
이렇게 생각보다 output이 labels를 잘 분류하는 것을 알 수 있다. 그런데 필자의 최종 목표는 instance segmentation이기 때문에 watershed 알고리즘을 적용하였다. 아래 그림은 바로 위 그림의 첫번째 output에 적용한 결과인데
노란색 타원으로 표시한 부분처럼 touching instances들도 구분한 것을 알 수 있다. + watershed 알고리즘 객체를 분할하는데 사용되는 기법으로 지형학적 모델을 사용하여 이미지의 픽셀을 분할하는기 때문에 outputs의 각 클래스별 출력이 높이로 간주된다. 이 알고리즘은 물이 채워질 때 계곡을 따라 경계가 형성된다는 개념에서 유래됐다. 알고리즘의 단계로는 1. 전처리 - threshold 보다 낮은 값들은 제거한다. 2. 거리 변환 - 객체 내부의 각 픽셀이 가장 가까운 배경 픽셀로부터 얼마나 떨어져 있는지 계산한다. 여기서 거리는 Manhattan distance를 의미한다. 3. 마커 생성 - 지역 극대값을 찾아 마커로 설정한다. 마커는 객체의 중심을 나타낸다. 4. watershed 변환 - 마커에서 시작하여 물을 채워 나가, 서로 다른 마커에서 채워진 물이 만나는 지점에서 경계가 형성된다. 가 있고 그 결과 위 그림처럼 instance segmentation이 수행된다.
Watershed 알고리즘을 진작에 알았다면 loss를 설계하는 과정이 더 논문에 가까워졌을 것 같지만 이 정도만으로 만족하고 넘어가려한다. 그리고 이건 위 모델하고는 상관없는데 생각보다 kaggle notebook이 괜찮은거 같다. Colab pro를 결제해도 다 쓰는데 1주일 밖에 걸리지 않는데 kaggle notebook은 전화번호가 있는데로 쓸 수 있고 1주일마다 다시 30시간을 사용할 수 있기 때문에 앞으로 대부분의 작업을 kaggle에서 사용할 것 같다. 다음 포스트는 동아리 사람들과 diffusion 모델 스터디를 하게 되어서 스터디 준비용 포스트를 올릴 것 같다. 바이~
벌써 2024년의 절반이 끝이 났다. 학업적으로 이룬 것을 나열해보면 1. 대학원 수업 2개 끝까지 듣기 2. 비타민 CV 프로젝트 끝내기 3. 학점 4/4.3 넘기기 4. 매주 블로그 하나씩 올리기
이외에도 연합전공인 인공지능을 하게 되어서 다음학기에 들을 수업이 늘어났다.
재수강 안치웠는데 이게 되네..?
생각보다 학업을 병행하니 개인 공부할 시간이 부족했고 비타민 프로젝트에도 많은 에너지를 쏟을 수는 없었던 것이 아쉽다(더 잘할 수 있었을 거 같은데..). 인생 계획이 바뀌어서 군대를 내년 초에 가게 되니 2024년 7월~2025년 2월까지의 계획을 세우게 되었다.(일단 오늘은 여름방학 계획만) 우선 크게 여름방학에는 비타민 마무리, 2학기에는 구글 머신러닝 부트캠프 수료 및 학점 관리 겨울방학에는 연구실 or 기업 인턴하기 가 내 계획이다.
에타에서 보고 흥미로워보여서 지원을 해봤는데 사실 이게 될 줄 몰랐다..(물론 지원서는 1주동안 열심히 고민..) 무려 500명의 사람이랑 같이 하는 거라 어떤 사람들을 만날지 궁금하지만 한편으로는 비대면이어서 거의 사람들하고 이야기도 못한채 끝날 수도 있을 것 같다.(그만큼 내가 이 기회를 어떻게 살릴지 중요할 것 같다.) 그래도 매주 해야하는 미션이 있고 현업에서 종사하시는 분들의 이야기를 들을 수 있는 기회, 반드시 캐글에서 성적을 내야하는 등 재미있어 보이는 것은 많아 기대된다. -> 사람들 만나보니까 대단한 사람들이 엄청 많다. 스스로 독학하시는분, 이미 경험이 많으신분, 해외 거주, 해외 유학 등등 다양한 분들이 계신다. 오프라인 교류가 적은게 좀 아쉽네..
아무튼 구글 부트캠프는 이렇고 내 여름방학 학업 계획은 다음과 같다. 1. 데이콘 FSI AlxData Challenge 2024 2. 캐글 playgound 20% 달성 3. 계절학기 드랍 안하기 4. 생성 모델(diffusion) 스터디 5. 매주 티스토리 3개씩 올리기 6. 백준 알고리즘 골드 달기 7. C++ 공부하기 8. LG Aimers 9. velog 내용 tistory로 옮기기
추가로 해야할 것은 졸업 계획 짜기, 여행 가기, 운동 하기 등등이 있겠다.(언제 다하지?) 아무튼 방학 목표 중에 80%만 해도 만족할 거 같고 티스토리에 올릴 것들을 나열하면 다음과 같다.
1. 'Attention is All You Need" 논문 리뷰 2. ViT 논문 리뷰 + 구현 3. CNN, RNN 개념 정리 및 구현 4. LSTM 논문 리뷰 + 구현 5. GRU 논문 리뷰 + 구현 6. Semi-Supervised Learning 복습하기 7. Self-Supervised Learning 복습하기 8. 딥러닝을 위한 수학 책 읽고 리뷰 9. U-Net bio image 실습 -> 완료
마지막으로 기말고사 마치고 종강을 위해 과제하다가 오민환 교수님의 말씀이 참 와닿아서 남겨보겠다.
제가 이 분야에서 오래 몸담으면서 깨달은 바는, 유행은 시간이 지나면 사라지지만 기초가 튼튼한 사람은 어디서든 필요로 하는 인재가 된다는 것입니다.
Deep nets가 성공적으로 훈련되기 위해서는 많은 annotated training samples가 필요하다고 알려져있다. 우리는 이 논무네서 이용가능한 annotated samples를 더 효율적으로 사용하기 위해 data augmentation을 활용하는 훈련 전략과 network를 소개하려 한다. 그 구조는 context를 캡처하는 contracting path와 정밀한 localization을 가능하게 하는 대칭적인 expanding path로 이루어져있다. 우리는 이 network가 end-to-end 방식으로 학습 가능한데 매우 작은 이미지더라도 기존의 방법인 sliding-window 방식을 능가하는 것을 보일 것이다.(데이터는 ISBI challenge for segmentation of neural structures in electron microscopic stacks) 같은 네트워크를 transmitted light microscopy images에도 훈련하여 ISBI cell tracking challenge 2015에서 가장 좋은 성능을 보였다. 게다가 이 네트워크는 바르다. 512*512 images를 GPU를 사용하여 inference하는데 일 초 이내의 시간이 걸린다.
< comment >
저자들이 소개하는 U-net은 기본적으로 FCN의 구조를 따르지만 몇가지 차이점이 존재한다. 대표적인 예시가 contracting path와 expanding path가 symmetric하다는 점인데 뒤에서 자세히 소개하도록 하고 U-Net에서 또 주목할만한 부분은 적은 이미지로도 높은 성능을 달성하기 위해 data augmentation을 사용했다는 점이다. 이는 biomedical image dataset의 특성과 관련되는데 이 dataset은 이미지의 크기가 다양하면서 대부분 크고 개수가 적다는 특징이 있다. 이를 보안하기 위해 U-Net이 어떻게 설계되었는지 차차 알아가보자.
1. Introduction
< 내용 >
지난 2년동안 deep convolutional networks는 많은 visual recogniton tasks에서 sota를 달성했다. 이러한 성공이 오랜시간 지속되었지만 그들의 성공이 제한되었던 것은 이용가능한 training set의 사이즈와 네트워크 자체의 크기 때문이다. Krizhevsky의 돌파구로 800만 개의 매개변수를 가진 8개의 레이어로 구성된 대규모 네트워크를 ImageNet 데이터셋의 100만 개의 훈련 이미지로 supervised training한 사례가 있고 그 이후로, 더 크고 깊은 네트워크들이 훈련되었다.
일반적으로 convolutional networks가 사용된 곳은 classification tasks이고 이는 이미지를 단일 클래스 label로 분류하는 문제이다. 그러나 많은 visual tasks, 특히 biomedical image processing은 이러한 output에 localization을 요구하였고 이는 우리가 아는 segmentation으로 각 pixel마다 class label을 assign하는 문제이다. 게다가 수천여장의 이미지가 주로 biomedical tasks에 존재한다.(확실히 적은 수치이다.) 따라서 Ciresan은 sliding-window setup을 통해 네트워크를 훈련하여 각 픽셀별 class label을 예측하고자 하였고 픽셀을 둘러싼 영역(이미지의 작은 부분인 패치)를 입력으로 삼았다. 먼저 이러한 네트워크는 localize가 가능했고 다음, patch를 입력으로 받기 때문에 training data의 개수는 images 전체를 입력받을 때보다 많았다. 그 결과 이 네트워크는 ISBI 2012 EM segmentation challenge 에서 큰 차이로 우승하였다.
확실이 Ciresan의 전략은 두 가지 단점이 존재한다. 먼저, 네트워크가 각 패치마다 개별로 진행되어야 하기 때문에 매우 느렸고 patches 간의 overlapping으로 매우 많은 redundancy가 존재했다. 다음으로, localization accuracy와 use of context사이에 trade-off가 존재했다. 큰 패치는 많은 max-pooling layers를 요구하여 localization accuracy를 낮추었고, 반면 작은 패치는 네트워크가 작은 context만 보게 하였다. 더 최근 접근방법에는 classifier output을 multiple layers에서 설명하는 방법이 있어 good localization과 use of context가 동시에 가능하도록 한다.
이 논문에서 우리는 더 세련된 구조인 fully convolutional network를 만들었다. 우리는 이 구조를 수정하고 확장하여 매우 작은 training images에서 precise segmentation을 수행하게 하였다.
FCN의 메인 아이디어(저번 포스팅에 올렸던 논문)는 일반적인 contracting network를 pooling operators를 upsampling operators로 대체한 succesive layers로 보충하는 것이다. 따라서 이 층은 output의 해상도를 중가시키니다. Localize를 위해서 contracting path의 high resolution feautres가 upsampled output과 결합한다. 이 연속적인 convolution layer은 정보의 output들을 ensemble 하여 학습한다.
우리의 구조에서 중요한 수정은 upsampling part에서도 큰 숫자의 feature channels를 가졌다는 것이다. 이는 network가 higher resolution layers로 context information을 전달하도록 한다. 그 결과 expansive path는 거의 contracting path와 symmetric하여 u-shaped architecture을 구성하게 된다. 이 네트워크는 fully connected layers를 갖지 않고 각 합성곱의 유용한 부분만 사용한다. 즉, segmentation map은 입력 이미지에서 전체 context가 사용 가능한 pixels만 포함되는데 overlap-tile strategy를 추가로 사용하여 임의의 큰 이미지에서 매끄러운 segmentation이 가능하게 한다. 이미지의 경계에 해당하는 pixels를 예측하기 위해 missing context를 input image에 mirroring을 통해 extrapolate한다. 이 tiling strategy는 네트워크에 큰 이미지를 적용하는데 중요한데 왜나하면 이렇게 하지 않는 경우 GPU memory에 의해 제한될 수 있기 때문이다.
우리의 tasks는 매우 작은 training data가 이용가능하기 때문에 우리는 강력한 data augmentation인 elastic deformation을 training images에 수행한다. 이것은 network가 이러한 deformations에 대해 invariance를 갖게 만든다. 이는 특히 biomedical segmentation에서 아주 중요한데 왜냐하면 tissue에는 이러한 변형들이 자주 일어나고 실제의 변형들을 효과적으로 재현할 수 있기 때문이다. Unsupervised feature learning의 범위에서 learning invariance에 대한 data augmentation의 가치는 Dosovitsky에 의해 알려져있다.
많은 cell segmentation에서 또다른 어려움은 same class의 접촉하는 objects를 분리하는 것이다. 마지막에 우리는 weigted loss를 제안하여 touching cells의 사이를 background labels로 여겨 분리하고 이 부분에 높은 가중치를 부여하는 loss function을 만들 것이다.
결과적으로 생성된 network는 다양한 biomedical segmentation problems에 적용가능하다. 이 논문에서 우리는 EM stacks(an ongoing competition started at ISBI 2012)에서 segmentation of neuronal structures의 결과를 보여줄 것이고 우리는 이 대회에서 Ciresan의 결과를 뛰어넘었다. 뿐만 아니라, ISBI cell tracking challenge 2015의 light microscoy images cell segmentation에서의 결과를 보여줄 것이다. 우리는 2D trasmitted light datasets에서 큰 차이로 우승하였다.
< comment >
저자들은 FCN의 구조를 확장하여 더 정확한 segementation이 가능한 구조를 만들었다. Expanding path(upsampling path)에 연속적인 layers를 보충하였고 많은 수의 채널을 갖게 설계하였다. 그 결과 두 경로가 대칭인 u-shape의 구조를 갖게 되었다. 또한 padding 없이 convolution을 수행하는 것이 특징인데 그럼 layer를 통과할 수록 크기가 줄어들어 이를 보충하기 위해 mirroring extraplation을 사용하였다. 뿐만 아니라 elastic deformation을 통한 data augmentation을 통해 작은 수의 이미지로도 충분한 성능을 내도록 하였고 instance segmentation을 수행하기 위해 touching cells 사이를 background처럼 인식하고 가중치를 부여하였다.
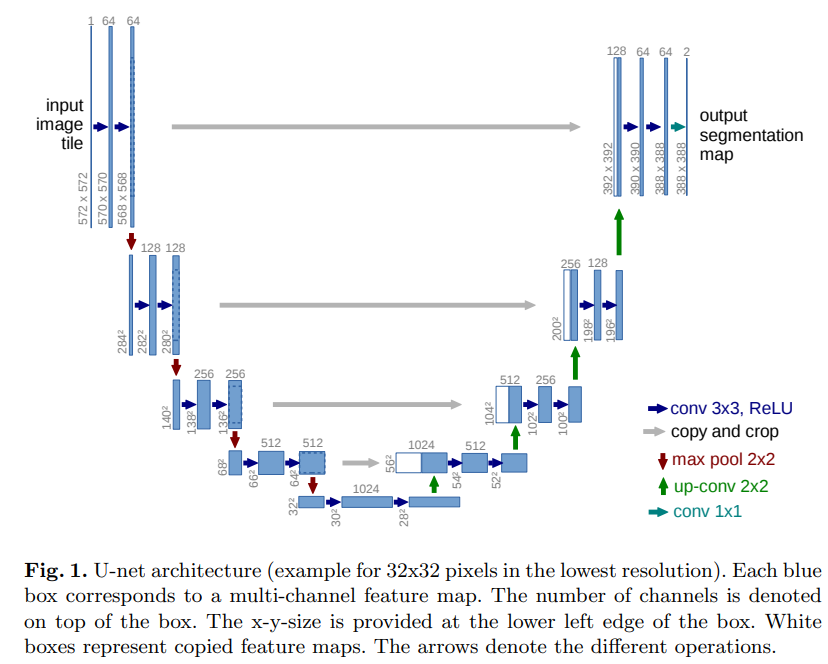
2. Network Architecture
< 내용 >
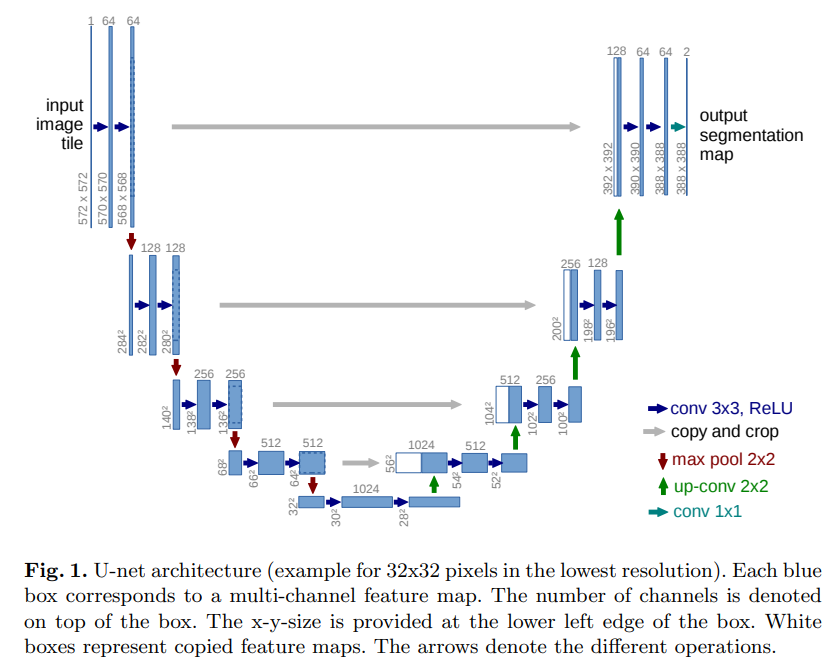
네트워크의 구조는 우와 같이 묘사되며 왼쪽의 contracting path와 오른쪽의 expanding path로 이루어진다. Contracting path는 일반적인 convolutional network의 구조를 따라한다. 이는 반복되는 두개의 3*3 convolutions(unpadded convolutions)로 이루어져있고 각각은 ReLU를 이어받는다. 그리고 2*2 max pooling operation with stride 2가 convolution layers 사이에 존재해 downsampling한다. 한번의 downsampling이 일어나면 feature channels는 두배가 된다. Expansive path의 모든 step에는 feature map의 채널 수를 절반으로 줄이는 2*2 합성곱 을 통해 upsampling하고 대응되는 크기로 잘라낸 contractin path의 결과와 연결된 후 두번의 3*3 합성곱(각각은 ReLU를 사용)으로 구성된다. . Cropping이 필수인데 every convolution에서 border pixels를 잃기 때문이다. 마지막 레이어의 1*1 convolution은 64개의 component feature vector을 요구되는 class의 숫자에 맞게 mapping하는데 쓰여 총 network는 23개의 convolution layers를 갖는다.
Segmenatation map의 output이 매끄럽기 위해선 2*2 max-pooling operations에 들어가는 input tile size가 짝수여야 한다.
< comment >
구조는 contracting path와 expanding path로 이루어져 있고 segmentation이 매끄럽게 수행되기 위해선 2*2 max-pooling operations에 들어가는 tile의 사이즈가 짝수여야한다.
3. Training
< 내용 >
Input image와 대응되는 segmentation maps는 Caffe에 구현된 stochastic gradient descent를 통해 훈련된다. Unpadded convolution 때문에 output image는 input image보다 작다.(by a constant border width) GPU memory의 overhead를 최소화하고 gpu를 최대로 사용하기 위해서 우리는 large input tiles를 large batch size보다 선호한다. 따라서 batch size를 1로 하여 단일 이미지를 사용하였다. 우리는 high momentum인 0.99를 사용하여 이전에 보았던 training samples들의 대부분이 current optimization step의 update에 사용되도록 하였다.
Energy function은 마지막 feature map의 pixel-wise soft-max와 cross entropy loss function을 결합한 함수를 사용하였다. soft-max는 pk(x)=exp(ak(x))/(∑Kk′=1exp(a′k(x)))로 정의되고
exp(a′k(x)) 는 x( x∈ΩwithΩ⊂Z2 )의 feature channel k의 activation을 의미한다. K는 classes의 number를 의미하고 pk(x)는 approximated maximum function이다.
*approximated maximum function
일반적으로 cross-entropy loss에 log안에 들어가는 값은 실제 분포를 추정한 모델의 확률로 U-net의 마지막 layer의 출력값이다. 그러나 특정 layer의 값을 단순히 대입하는 것은 미분이 불가능하기 때문에 미분가능한 값으로 만들기 위해 approximation funtion을 사용한다.
즉 이 값이 1에 가깝다는 것은 대응되는 k에 대해 maximum activation을 갖는 것이고 다른 k에 대해서는 이 값이 0에 가깝다. Cross entropy는 −∑ni=1p(xi)log(q(xi))인데 class segmentation인 p(xi)가 실제 레이블에서만 1이므로 최대화하려는 energy funtion은 다음과 같이 정의된다.
E=∑x∈Ωw(x)log(pl(x)(x))
여기서 l은 each pixel의 true label을 의미하고 w는 weight map으로 몇몇의 pixels에 더 중요하게 생각하기 위해 도입한 것이다.
먼저 우리는 wegith map을 certatin class의 different frequency of pixels를 반영하여 보상하기 위해 pre-compute한다. 이후에 가중치를 update하여 touching cells 사이에 있는 small separation borders도 학습할 수 있게 한다.
가중치 update는 morphological operations(형태학적 작용)을 통해 계산되는데 식은 다음과 같다.
w(x)=wc(x)+w0⋅exp(−(d1(x)+d2(x))22σ2)
wc는 class frequencies를 balance한 weight map이고 d1은 가장 가까운 셀의 경계 까지의 거리, d2는 두번째 가까운 셀의 경계까지의 거리이다. 우리의 실험에는 w0=10, σ≈5 pixels이다.
Deep networks에서 많은 convolution layers와 network를 통과하는 다양한 경로가 존재하면 weights의 초기 initialization은 매우 중요하다. 그렇지 않으면 네트워크의 일부가 과도하게 활성화되어 다른 부분은 전혀 기여하지 않을 수 있다. 이상적으로는 네트워크의 각 피처 맵이 단위 분산을 갖도록 초기 가중치를 정해야 한다. 교대로 발생하는 convolution 과 ReLU layers가 있는 우리의 구조에서는 이 목표를 달성하기 위해 표준 편차가 √2/N인 가우시안 분포에서 초기 가중치를 추출하였다. 여기서 N은 한 뉴런의 입력 노드 수를 의미한다. 예를 들어 이전 층에 64개의 채널이 있는 3*3 합성곱의 경우 N은 9*64=576이다.
3.1 Data Augmentation
Data augmentation은 매우 적은 training samples가 이용가능할 때 network에 invariance와 robustness properties를 가르치는데 필수적이다. Microscopial images의 경우 우리는 주로 여러 변형에 대한 robustness 뿐만아니라 shift와 rotation invariance, gray value varations에 대한 invariance 까지 필요하다. 특히 random elastic deformations를 training sample에 적용하는 것이 매우 적은 annotated images에서 segmentation을 수행하는 network를 훈련시킬 때 주요해보인다. 우리는 3*3 격자에서 랜덤한 변위 벡터를 사용하는 smooth deformations를 생성하였다. 변위는 표준 편차가 10 픽셀인 가우시안 분포에서 샘플링하였다. 각 픽셀의 변위는 bicubic interpolations에 의해 계산된다. 수축 경로 끝에 있는 Drop-out layers는 암묵적인 data augmentation을 추가적으로 수행한다.=
< comment >
U-Net은 biomedical image의 사이즈가 크다는 특성 때문에 patchwise training을 사용한다. 이 과정에서 큰 input tiles를 선호해 batchsize는 최소화하여 1을 사용하였다. 또한 optimize할 때 momentum을 0.99인 큰 값을 사용하여 이전 이미지가 현재에 대부분 영향을 주도록 설계하였다.
Loss funtion은 pixel-wise softmax function과 cross-entropy loss를 결합하여 설계하였고 weight를 도입하여 class간의 frequency, touching cells 사이에 위치했는가를 반영하였다. 그리고 중요한 초기 가중치 설계를 입력 노드를 고려한 가우시안 분포에서 추출하였다.
4. Experiments
< 내용 >
< comment >
U-Net은 다양한 bio-medical image segmentation에서 좋은 성능을 보인다.
5. Conclusion
< 내용 >
U-net 구조는 다양한 biomedical segmentation applications에서 좋은 성능을 달성하였다. Elastic deformations를 사용하는 data augmentation에 힘입어 매우 작은 annotated imges만 필요하고 타당한 training time을 소요한다. Caffe-based implementation과 trained networks를 제공한다. 우리는 u-net architecture이 다른 더 많은 tasks에서 쉽게 적용될 것을 장담한다.
< comment >
U-net은다양한 biomedical segmentation application에서 좋은 성능을 보이고 사용한 주요 techniques는 u-shaped architecture(with layers and channels), overlap-tile strategy & mirroring extrapolation, data augementation(by. elastic deformation)이다.
# 원본 이미지 및 마스크 경로
images_src_dir = './png_images/IMAGES'
masks_src_dir = './png_masks/MASKS'
# 타겟 디렉토리 설정
train_images_dir = 'dataset/train/images'
train_masks_dir = 'dataset/train/masks'
val_images_dir = 'dataset/val/images'
val_masks_dir = 'dataset/val/masks'
# 타겟 디렉토리가 존재하지 않으면 생성
os.makedirs(train_images_dir, exist_ok=True)
os.makedirs(train_masks_dir, exist_ok=True)
os.makedirs(val_images_dir, exist_ok=True)
os.makedirs(val_masks_dir, exist_ok=True)
# 원본 이미지 디렉토리의 모든 파일 목록 가져오기
all_images = os.listdir(images_src_dir)
# 이미지를 랜덤하게 섞기
random.shuffle(all_images)
# 검증셋과 훈련셋으로 나누기
val_images = all_images[:100]
train_images = all_images[100:]
# 이미지와 매칭되는 마스크 파일 복사
for img_name in val_images:
# 이미지 파일 복사
shutil.copy(os.path.join(images_src_dir, img_name), os.path.join(val_images_dir, img_name))
mask_name = img_name.replace('img', 'seg')
shutil.copy(os.path.join(masks_src_dir, mask_name), os.path.join(val_masks_dir, mask_name))
for img_name in train_images:
# 이미지 파일 복사
shutil.copy(os.path.join(images_src_dir, img_name), os.path.join(train_images_dir, img_name))
mask_name = img_name.replace('img', 'seg')
shutil.copy(os.path.join(masks_src_dir, mask_name), os.path.join(train_masks_dir, mask_name))
print("이미지와 마스크 파일의 분할이 완료되었습니다.")
전체가 1000장이어서 100장을 validation set에 넣었고 이미지 파일을 복사하기 위해서 shutil이라는 메서드를 사용하였다.
이 과정의 프로세스만 이야기하면 이미지가 전체 들어있는 디렉토리에 속해이는 모든 파일을 all_images에 가져오고, random.shuffle()을 통해 이를 랜덤하게 섞은 다음 그 중 앞에 있는 100개를 val_images에 분류하였다. 그 후 os.path.join()과 shutil.copy(a, b)를 통해 a의 이미지를 복사하여 b에 붙여넣었다. 그 후 파일명을 확인했을 때 image와 mask의 차이가 img과 seg로 되어 있어(뒷부분은 동일) 이렇게 replace하고 mask도 저장해주었다.
이 결과
dataset
- train --images
--masks
-val -- images
-- masks
로 저장되었다.
이번엔 데이터 로더에 데이터를 로드해볼 것인데
classSegmentationDataset(Dataset):def__init__(self, images_dir, masks_dir, transform=None, target_transform=None):
self.images_dir = images_dir
self.masks_dir = masks_dir
self.transform = transform
self.target_transform = target_transform
self.images = sorted(os.listdir(images_dir))
self.masks = sorted(os.listdir(masks_dir))
self.images = [img for img in self.images if os.path.isfile(os.path.join(images_dir, img))]
self.masks = [msk for msk in self.masks if os.path.isfile(os.path.join(masks_dir, msk))]
def__len__(self):returnlen(self.images)
def__getitem__(self, idx):
img_path = os.path.join(self.images_dir, self.images[idx])
mask_path = os.path.join(self.masks_dir, self.masks[idx])
image = Image.open(img_path).convert('RGB')
mask = Image.open(mask_path).convert('L')
if self.transform:
image = self.transform(image)
if self.target_transform:
mask = self.target_transform(mask)
mask = torch.tensor(np.array(mask), dtype=torch.float32).unsqueeze(0)
return image, mask
# 데이터 전처리# resize, to tensor, normalization# 이외에도 centor crop. gr# 이외에도 centor crop. grapyscale, random affine transformations# 이외에도 centor crop. grapyscale, random affine transformations# random crop, ramdom horizontal flip, color jitter, 등의 방법이 있음.
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
target_transform = transforms.Compose([
transforms.Resize((256, 256)),
# transforms.ToTensor(),
])
train_images_dir = './dataset/train/images'
train_masks_dir = './dataset/train/masks'
val_images_dir = './dataset/val/images'
val_masks_dir = './dataset/val/masks'
train_dataset = SegmentationDataset(train_images_dir, train_masks_dir, transform=transform, target_transform=target_transform)
val_dataset = SegmentationDataset(val_images_dir, val_masks_dir, transform=transform, target_transform=target_transform)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False)
이렇게 SegmentationDataset이라는 class를 정의하고 Dataset 클래스를 상속받는 class에서 정의하는 __len__함수와 __getitem__함수를 정의해주었다. Dataset의 masks는 gray scale이고 각 픽셀의 값이 class를 의미하기 때문에 .convert('L')을 해주었고 images는 .convert('RGB)를 해주었다. 이후 images와 masks 각각에 적절한 데이터 전처리를 해주었는데 공통은 Resize((256, 256))이고(사실 안해주어도 구현이 가능하나 계산의 용이성을 위해 처리하였다.) images는 ToTensor()와 Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])를 mask에는 torch.tensor(np.array(mask), dtype=torch.float32).unsqueeze(0)를 적용해주었는데 그 이유는 segmentation에서는 대부분 mask의 각 값이 class를 의미하기 때문에(gray scale인 경우 더 그럴 확률이 높다.) Normalize를 하지 않고 그 값을 보존해야 했기 때문이다. 파이토치의 transforms.ToTensor()은 0~1사이로 scale하는 과정이 포함되기 때문에 이 방법이 아닌 torch.tensor(np.array(mask), dtype=torch.float32).unsqueeze(0)을 사용하였다. 이후 DataLodaer함수를 통해 train_loader와 val_loader에 batch_size=8로 데이터를 로드해주었다.
+
self.images = [img for img in self.images if os.path.isfile(os.path.join(images_dir, img))]
self.masks = [msk for msk in self.masks if os.path.isfile(os.path.join(masks_dir, msk))]
이 부분은 jupyter notebook이 자체적으로 안보이는 ipynb 파일을 생성해서 필터링해주는 부분이다.
++
마스크의 데이터가 어떻게 생겼는지 확인하기 위해 masks.max().item()을 출력하면 다음과 같다.
# Mask 범위 확인for images, masks in train_loader:
max_value = masks.max().item()
print(f'Max value in masks: {max_value}')
break# 첫 번째 배치의 최댓값만 확인하기 위해 반복문 종료
Max value in masks: 54.0
모델을 정의하기전 데이터를 시각화 해보겠다.
정규화가 진행되었기 때문에 정규화를 역변환하는 함수를 정의하고 시각화 하는 함수를 정의한 다음 첫번째 배치의 5번 index를 시각화 해보았다.
## 데이터 시각화# 정규화 역변환 함수defdenormalize(image_tensor, mean, std):
mean = np.array(mean)
std = np.array(std)
image = image_tensor.permute(1, 2, 0).cpu().numpy() # CHW -> HWC
image = std * image + mean # 정규화 역변환# clipping: 0보다 작으면 0, 1보다 크면 1로 변환# 값이 비정상적으로 크거나 작아지는 것을 방지하는 역할
image = np.clip(image, 0, 1) # [0, 1] 범위로 클리핑# 이미지 시각화 라이브러리(OpecV, matplotlib 등)은 이미지 데이터를 0에서 255 범위의# 8비트 정수 형태로 다루기 때문에 정규화된 [0,1] [0,255]로 변환
image = (image * 255).astype(np.uint8) # [0, 1] -> [0, 255]return image
defimshow(image_tensor, mask_tensor, mean, std):
image = denormalize(image_tensor, mean, std) # 정규화 역변환 적용# 채널 차원 제거, cpu로 이동, numpy 배열로 변환
mask = mask_tensor.squeeze(0).cpu().numpy()
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title('Image')
plt.axis('off')
plt.subplot(1, 2, 2)
# color map을 지정하는 인자, 그레이스케일 컬러 맵을 사용하여 이미지를 시각화함.
plt.imshow(mask, cmap='gray')
plt.title('Mask')
plt.axis('off')
plt.show()
# 데이터셋에서 배치 하나를 로드하여 시각화# 데이터 로더는 각 배치를 (input, target) 형태로 반환함.# iter는 데이터로더 객체에 대한 이터레이터를 생성해 순차적으로 배치를 가져오게 함# next는 이터레이터에서 다음 배치를 가져옴.
images, masks = next(iter(train_loader))
print("배치의 크기:",images.size())
print("이미지의 크기:",images[0].size())
# 정규화 역변환에 필요한 mean과 std -> ImageNet dataset에서 생성됨.
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# 첫 번째 이미지와 마스크 시각화
imshow(images[5], masks[5], mean, std)
matplotlib.pyplot의 imshow는 단일 채널의 경우 2D 배열, 단일 채널이 아니라면 3D 배열을 입력 받고 마지막 차원을 채널로 인식하기 때문에 RGB 채널인 image는 permute(1,2,0)을 통해 CHW 차원을 H,W,C 순서로 바꿔주었고 mask는 C 차원을 없애 주었다. 또한 scaling을 image에서만 했기 대문에 image = np.clip(image, 0, 1)과 image = (image*255).astype(np.unit8)을 통해 matplotlib가 원하는 0부터 255사이의 8비트 정수 형태로 만들어주었다.
이후 plt.subplot()을 통해 왼쪽에는 이미지, 오른쪽에는 mask를 시각화하였다.
특이한 부분은 첫번재 conv_block에서 첫 conv2d의 padding이 무려 100이라는 점!! 그리고 upsampling이 학습되도록 ConvTranspose2d라는 함수를 사용하였다는 점, pooling layer의 결과와 upsampling layer의 결과를 합치기 위해 cropping하는 부분이 있다는 점, FCN-8s의 모델의 가중치를 사전 훈련된 VGG16 모델의 가중치로 초기화했다는 점이 있겠다.
좀 더 자세히 알아보기 위해 다음의 코드들을 살펴보았는데
# 모델의 모든 모듈을 순회하면서 nn.ConvTranspose2d 레이어의 가중치를 초기화 하는 역할for m in self.modules():
ifisinstance(m, nn.ConvTranspose2d):
m.weight.data.copy_(
get_upsampling_weight(m.in_channels, m.out_channels, m.kernel_size[0])
)
defget_upsampling_weight(in_channels, out_channels, kernel_size):"""Make a 2D bilinear kernel suitable for upsampling"""# 커널의 중앙 계산
factor = (kernel_size + 1) // 2if kernel_size % 2 == 1:
center = factor - 1else:
center = factor - 0.5# 그리드 생성# ogrid -> 열린 그리드 생성
og = np.ogrid[:kernel_size, :kernel_size]
# 양선형 보간 필터 생성
filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
# 가중치 텐서 초기화
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype=np.float64)
weight[range(in_channels), range(out_channels), :, :] = filt
# pytorch 텐서로 변환return torch.from_numpy(weight).float()
nn.ConvTranspose2d layer의 초기 가중치를 양선형 보간법으로 초기화해야 해서 양선형 보간법의 가중치를 넣어주어야 했다. Channel과 kernel의 사이즈에 맞는 가중치를 생성하기 위해 get_upsampling_weight 함수는 위와 같이 정의하여 만들어주었고 동작원리는 다음과 같다.
먼저 weigth를 0으로 초기화 하고 weight[i, j, :, :]은 i=j 일때만 filt로 초기화 한다. 그 후 tensor로 변환해 return
returnout.contiguous()
다음은 contoguous()에 관한 설명인데 out.contiguous()는 PyTorch 텐서의 메모리 연속성을 보장하기 위해 사용되는 메서드로 이를 이해하려면 먼저 텐서의 메모리 구조와 연속성의 개념을 이해해야 한다.
PyTorch에서 텐서는 메모리에 저장될 때 특정한 순서로 배열된다. 메모리에서 텐서의 요소가 어떻게 배치되는지에 따라 텐서가 연속적(contiguous)일 수도 있고, 비연속적(non-contiguous)일 수도 있는데.
연속적 텐서: 모든 요소가 메모리에서 순서대로 저장되어 텐서의 요소들이 메모리에서 끊김 없이 배치된다.
비연속적 텐서: 요소들이 메모리에서 순서대로 배치되지 않을 수 있는데 특히, 슬라이싱 연산이나 전치(transpose) 연산 후의 텐서는 비연속적일 수 있다.
연산을 수행하는 동안, PyTorch 텐서는 비연속적일 수 있는데 일부 연산은 연속적 텐서에서만 제대로 동작하므로, 비연속적 텐서를 연속적 텐서로 변환할 필요가 있다. 이때 contiguous() 메서드를 사용하여 텐서를 복사하여 새로운 메모리 블록에 연속적으로 저장된 텐서를 반환한다.
3. 모델, 손실함수 및 옵티마이저 설정
그 다음 모델 instance를 생성하고 가중치 초기화와 손실함수는 CrossEntropyLoss()로, 옵티마이저는 Adam(lr=0.00001)로 설정하였다.
num_epochs = 100# 모델 훈련 모드
fcn_model.train()
for epoch inrange(num_epochs):
# 누적 손실
running_loss=0.0for images, masks in train_loader:
images = images.to(device)
masks = masks.to(device)
# 이전 배치의 경사도를 초기화 함.# 각 배치마다 손실함수의 경사도를 계산하고 이를 통해 모델의 파라미터를 업데이트 하는데# 기본적으로 경사도가 누적되므로 초기화 해야 함.
optimizer.zero_grad()
outputs = fcn_model(images)
# 채널 차원 재거하고 'long'타입으로 변환# nn.CrossEntropyLoss 쓰려고 채널 차원 제거# 파이토치에서 long 타입은 64비트 정수를 의미. nn.CrossEntropyLoss에서 long 타입 사용
loss = criterion(outputs, masks.squeeze(1).long())
# 손실에 대한 경사도 계산
loss.backward()
# 모델의 파라미터 업데이트
optimizer.step()
# 현재 배치의 손실 값을 누적 손실에 더합
running_loss += loss.item()
# 에포크가 끝난 후 한 에포크의 손실 값은 배치 크기로 나눠주어 평균 손실 값을 출력print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader)}")
# 검증
fcn_model.eval()
val_loss = 0.0# 검증 시에는 경사도를 계산하지 않기 위해 메모리 사용량과 연산 속도를 최적화함.with torch.no_grad():
for images, masks in val_loader:
images = images.to(device)
masks = masks.to(device)
outputs = fcn_model(images)
loss = criterion(outputs, masks.squeeze(1).long())
val_loss += loss.item()
print(f"Validation Loss: {val_loss/len(val_loader)}")
fcn_model.train()
print("훈련 완료")
그 다음 단계는 훈련 과정인데 model.train()과 model.eval()의 차이와 nn.CrossEntropyLoss()에 대해 궁금한 부분을 조사해보았다.
먼저, 학습 모드와 평가 모드는 주로 다음과 같은 레이어에서 동작 방식이 달라진다.
Dropout 레이어:
학습 모드 (model.train()): Dropout 레이어는 각 훈련 단계에서 무작위로 일부 뉴런을 비활성화하여 과적합을 방지한다.
평가 모드 (model.eval()): Dropout 레이어는 모든 뉴런을 활성화하여 전체 모델을 사용합니다. 따라서 예측을 수행할 때 Dropout이 적용되지않는다.
Batch Normalization 레이어:
학습 모드 (model.train()): Batch Normalization 레이어는 미니배치의 평균과 분산을 사용하여 정규화한다.
평가 모드 (model.eval()): Batch Normalization 레이어는 학습 동안 계산된 전체 데이터셋의 이동 평균과 이동 분산을 사용하여 정규화한다.
loss = criterion(outputs, masks.squeeze(1).long()) 이런식으로 설정해주었다.
5. 결과 시각화
# 시각화 함수defvisualize(image_tensor, mask_tensor, pred_tensor, mean, std):
image = denormalize(image_tensor, mean, std) # 정규화 역변환 적용
mask = mask_tensor.squeeze(0).cpu().numpy() # Remove the channel dimension
mask = (mask * 255).astype(np.uint8)
pred = pred_tensor.argmax(dim=0).cpu().numpy() # 예측된 클래스
pred = (pred * 255 / pred.max()).astype(np.uint8) # 정규화
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.imshow(image)
plt.title('Image')
plt.axis('off')
plt.subplot(1, 3, 2)
plt.imshow(mask, cmap='gray')
plt.title('Ground Truth')
plt.axis('off')
plt.subplot(1, 3, 3)
plt.imshow(pred, cmap='gray')
plt.title('Predicted Mask')
plt.axis('off')
plt.show()
# 데이터셋에서 배치 하나를 로드하여 시각화
fcn_model.eval()
with torch.no_grad():
for images, masks in val_loader:
images = images.to(device)
masks = masks.to(device)
outputs = fcn_model(images)
# 정규화 역변환에 필요한 mean과 std
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# 첫 번째 이미지와 마스크 시각화
visualize(images[7], masks[7], outputs[7], mean, std)
break# 첫 번째 배치의 여덟 번째 이미지만 시각화
이미지 시각화와 비슷한 형태로 진행하였고 결과는 다음과 같다.
6. mean IOU 구하기
defcalculate_iou(pred, target, num_classes):
ious = []
# 비교를 위해 일차원으로 변환환
pred = pred.view(-1)
target = target.view(-1)
for cls inrange(1, num_classes):
pred_inds = (pred == cls)
target_inds = (target == cls)
intersection = (pred_inds[target_inds]).long().sum().item()
union = pred_inds.long().sum().item() + target_inds.long().sum().item() - intersection
if union == 0:
ious.append(float('nan')) # If there is no ground truth, do not include in IoUelse:
ious.append(float(intersection) / float(union))
iflen(ious) != 0andnot np.all(np.isnan(ious)):
return np.nanmean(ious) # Return mean IoU for all classeselse:
return0# 전체 데이터셋에 대한 Mean IoU 계산defmean_iou(model, data_loader, num_classes, device):
model.eval()
iou_list = []
with torch.no_grad():
for images, masks in data_loader:
images = images.to(device)
masks = masks.to(device)
outputs = model(images)
# 예측 클래스 레이블을 얻음
preds = outputs.argmax(dim=1)
for pred, mask inzip(preds, masks.squeeze(1)): # Remove channel dimension from masks
iou = calculate_iou(pred, mask, num_classes)
iou_list.append(iou)
return np.nanmean(iou_list)
# 모델과 데이터 로더 설정
device = torch.device('cuda'if torch.cuda.is_available() else'cpu')
num_classes = 59# 클래스 수 설정
fcn_model.to(device)
# Mean IoU 계산
mean_iou_value = mean_iou(fcn_model, val_loader, num_classes, device)
print(f"Mean IoU: {mean_iou_value}")
for cls inrange(1, num_classes):
pred_inds = (pred == cls)
target_inds = (target == cls)
intersection = (pred_inds[target_inds]).long().sum().item()
union = pred_inds.long().sum().item() + target_inds.long().sum().item() - intersection
if union == 0:
ious.append(float('nan')) # If there is no ground truth, do not include in IoUelse:
ious.append(float(intersection) / float(union))
iflen(ious) != 0andnot np.all(np.isnan(ious)):
return np.nanmean(ious) # Return mean IoU for all classeselse:
return0
각 class 별로 iou를 구한 다음 평균해주었다.
그 결과 출력은
Mean IoU: 0.10054701150414594
원래는 에포크별 mean iou를 출력하는 것이 더 일반적이나 까먹고 코드에 넣지 못해서..
이렇게 오늘은 FCN8s를 통해 cloth segmentation을 수행해보았다. 물론 github를 불러다 쓰면 쉽게 할 수 있지만 코드를 한줄한줄 짜보는 것도 의미가 있는거 같아 위 코드의 대부분을 수작업으로 짜보았다. 다음은 U-Net 논문 리뷰를 하고 U-Net을 코드로 구현해보는 시간을 가져보겠다.
티스토리의 첫 번째 포스트는 Jonathan Long, Evan Shelhamer, Trevor Darrell의 논문인 Fully Convolutional Networks for Semantic Segmentation에 대해 리뷰해 보겠다. 기존에 velog에 있지만 카테고리 정리에 유리한 tistory로 넘어갈 계획이라 이 논문을 기점으로 시작해 보겠다.(나머지 자료들도 차차 옮길 것)
본격적인 리뷰에 들어가기 앞서서 위의 ppt에서도 나와있다시피 CV에 대해 정리해 보았는데 이번 연도 목표는 CV분야를 깊게 파는 것이라 한번 정리해 볼 필요성을 느껴하게 되었다.
0. Computer Vision이란?
최근에 사서 잘 쓰고 있는 GPT-4에서 컴퓨터 비전을 물어보니 '컴퓨터 비전은 이미지나 비디오 데이터를 분석하여 인간의 시각적 인식 능력을 모방하는 기술', '컴퓨터 비전의 주요 목표는 기계가 시각적 데이터를 보고, 이해하며, 그 정보를 기반으로 판단할 수 있게 하는 것'이라는 답변을 얻었다. 여기서 키워드들을 뽑아보면 CV는 '이미지'나 '비디오 데이터'를 분석한다는 것이고, 이를 '이해'하는 것을 넘어서 '판단'하는 것이 목표라는 것이다. 따라서 이 '판단'의 난이도에 따라 컴퓨터 비전 tasks들의 혁신이 이루어졌는데 task에는 다음의 것들이 있다.
image classification(이미지의 클래스를 분류)
object detection(객체를 식별하고, 위치를 bb(bounding box)로 표시
image segmentation(이미지 내의 객체의 클래스를 분류하고 그 경계를 탐색)
pose estimation(인간의 자세를 추정)
image generation(새로운 이미지 생성)
이외에도 image restoration 등 다양한 tasks들이 있지만 일단 대충 유명한 것(아직 필자의 지식이 깊지 못하다.)을 나열하면 위와 같다. 이 중에서 가장 간단해 보이는 건 당연히 image classifcation이고 이 분야에서 혁신이 가장 먼저 이루어졌다. 오늘의 주제는 3번째에 있는 image segmentation인데 흐름상 혁신이 image classification -> object detection -> image segmentation으로 이루어졌지만 이 순서대로 발전이 이루어지고 있다는 생각은 바람직하지 않다. 왜냐하면 초기 혁신이 이 순서로 이루어진 것뿐이지 이후에는 서로가 서로에게 영향을 주면서 발전을 하고 있기 때문이다.
또한 흥미로운 점 중 하나가 image classification과 image segmentation은 본질적으로 같은 문제라는 점이다. 왜냐하면 image segmentation은 이미지 내에 존재하는 모든 객체의 클래스를 분류하고 경계를 찾는 것인데 이를 다르게 보면 이미지의 모든 pixel의 클래스를 분류하는 것과 같기 때문이다(그럼 자동으로 우리가 원했던 경계를 얻게 된다.). 따라서 image segmentation의 모델들은 classification 모델의 영향을 많이 받게 되었고 오늘의 FCN 논문에는 AlexNet, VGGNet, GoogLeNEt이 사용되었다.
그리고 segmenatation은 두 종류로 나뉘는데 먼저 같은 class의 instances를 구분하지 않는 semantic segmentation과 같은 class의 instances를 구분하는 instance segmentation이다. 당연히 이 둘 중 어려운 것은 instance단위로 구분하는 instancce segmentation이며 instance 간의 경계를 에 해당하는 pixels를 background로 인식한다.
사실 FCN은 image segmentation에서 첫 혁신을 가져왔는데 아무래도 다른 모델들에 비해 비교적 오래되고 현재에는 거의 사용되지 않는다.(그래봤자 2015년..) 그래서 처음에는 가볍게 코드만 리뷰하고 기본 개념들만 짚고 넘어가려 했지만 논문을 읽어보니 저자분들의 노고가 시행착오가 흥미로워 내용을 다루지 않을 수 없었다. 위의 발표자료에는 생략된 부분이 있어 모든 내용은 이 포스트를 읽어보면 될 것 같다.
추가로, GPT에게 FCN을 물어보니 'FCN은 이미지 세그멘테이션을 위해 특별히 설계된 최초의 딥러닝 모델 중 하나로, 전통적인 컨볼루션 네트워크를 수정하여 어떤 크기의 이미지도 처리할 수 있게 하고, 출력으로 픽셀 단위의 세그멘테이션 맵을 생성 합니다. 이는 업샘플링과 스킵 연결을 통해 세부적인 정보를 보전하면서 이루어집니다.'라는 답변을 받았다.
이제 본격적인 논문 리뷰로 넘어가 보자. 레츠고우
Abstract
< 내용 >
Convolutional networks는 features의 계층 구조를 시각화하는 강력한 모델이다. End-to-end 학습을 pixel 단위로 수행하는 것이 특징이고 semantic segmentation 분야에서 최신 기술들을 뛰어넘었다. 주요하게 쓰인 기술은 "fully convolutional" network를 형성하여 임의의 크기의 입력을 받아 효율적인 추론과 학습으로 대응하는 크기의 출력을 형성하는 것이다.
본 논문에서 space of fully convolutional networks를 정의하고 그들의 dense predictions(image의 모든 pixel에 대해 예측을 수행하는 것)에 어떻게 적용되는지 설명한다.
우리는 분류 문제에서 좋은 성능을 보인 AlexNet과 VGG Net, GoogLeNet을 fully convolutional networks로 변환하고 sementic segmentation에 맞게 fine-tuning 하는 방법을 사용한다.
또한, 새로운 구조(skip architecture)를 정의해 deep, coarse layer의 semantic information과 shallow, fine layer의 appearnace information을 결합한다.
그 결과 우리 모델은 다양한 데이터에서 좋은 성능을 보였고 한 이미지당 infernce에 걸리는 시간은 1/5초에 불과하다.
< comment >
Abstract에서 알아야 하는 내용이나 용어는 FCN이 end-to-end 학습에 dense prediction을 진행한다는 것, fully convolutional network, skip architecture 정도가 되겠다. 자세한 내용은 뒤에서 모두 소개된다.
1. Introduction
FCN이 fully convolutional network인 이유는 모든 층이 Conv layer이기 때문이다.
< 내용 >
Convolutional networks는 다양한 tasks에서 발전을 이끌고 있다. Whole-image classification 뿐만 아니라 특정 입력 영역에 구조화된 출력을 생성하는 작업에도 좋은 성능을 보인다.(bounding box object detection, part and keypoint prediction, local correspondence가 포함됨.) > Part and keypoint prediction: 이미지나 비디오에서 특정 부분이나 주요 지점을 예측하는 작업(ex. 눈코입의 위치) > Local correspondence: 두 이미지나 영상에서 서로 대응되는 지역을 찾는 작업. 이미지 매칭, 객체 추적, 광학 흐름(픽셀이 얼마나 움직였는지 추정)하는 작업을 포함한다.
자연스럽게 관심사는 coarse inference에서 pixel 단위의 예측을 수행하는 fine inference로 넘어가게 되는데 기존에 convnets을 활용하여 segmentation을 시도한 것들은 단점이 존재한다.
> coarse inference vs fine inference
앞으로 자주 나올 형용사 coarse와 fine인데 coarse는 추상적인 추론, fine은 세부적인 추론으로 이해하면 될 것 같다. Whole image classifcation과 image segmentation을 비교하면 whole image classification이 coarse inference, image segmentation이 fine inference에 속한다. 우리는 fully convolutional network(FCN)이 semantic segmentation에서 최신 성능을 보임을 입증했다. Pixelwise prediction과 surpervised pre-training(대규모 레이블이 있는 데이터셋에서 학습하는 pre-training과 특정 작업에 특화되도록 튜닝하는 fine-tuning으로 이루어짐)에 FCNs이 사용된 것은 처음이며 입력 크기에 제한을 받지 않는다. 전체 이미지에 대한 learning과 inference가 수행되며 upsampling layer는 픽셀 단위 예측과 다운샘플링된 풀링을 사용하는 네트워크에서의 학습을 지원한다.
이 방법은 점근적으로, 절대적으로 효율적이며 다른 방법의 복잡한 과정을 줄여준다. 먼저 patchwise training(전체 이미지의 일부분인 patch로 나누어 학습하는 방식)을 하지 않고 복잡한 pre- and post- processing(superpixels, proposals, post-hoc refinement by random fields, local classifiers)을 사용하지 않는다.
우리의 모델은 classification에서의 성공을 거둔 신경망을 fully convolutional 하게 바꾸고 그들의 가중치를 가져온 다음 fine-tuning을 진행한다. 반면에 이전 연구들은 supervised pre-training 없이 작은 convnet을 사용했었다. Semantic segmentation은 semantics와 location 사이의 균형이 중요한데 semantics = global information(deep, coarse)은 '무엇'에 관한 정보이고 location = local(fine, appearance)은 '어디'에 관한 정보이다.
우리는 이 균형을 새로운 'skip' architecture을 도입하여 local-to-global pyramid를 형성해 맞출 것이고 우리의 모델은 다양한 데이터 셋에서 좋은 성능을 보였다.
< comment >
따로 comment 할 내용은 크게 없고 FCN의 특징들이 나열되어 있다. 정리해 보면
end-to-end 바이고
pixel wise prediction
supervised pre-training
input의 크기에 대한 제약이 없어짐
복잡한 pre- and post- processing 사용 x
patchwise training x
skip architecture 도입
이 되겠다.
2. Related Work
< 내용 >
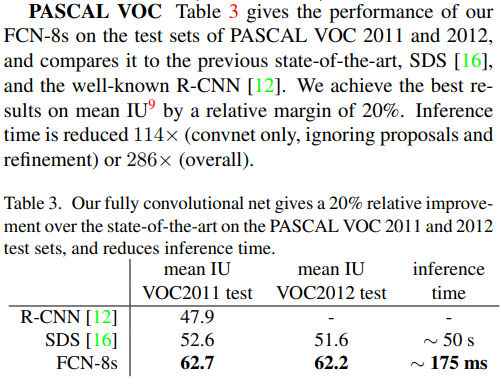
우리의 접근 방식은 image classification에서 딥러닝의 성공과 전이 학습을 기반으로 하고 있다. Classification nets를 re-architect 하고 fine-tuning 해 semantic segmentation을 위한 dense prediction을 수행하는 모델로 변환한다. Fully convolutional networks Convnet(합성공 신경망)을 확장하려는 시도는 aribitary-sized input을 받기 위한 노력으로 시작된다. 다른 사례론 convnet의 outputs을 2-dimensional maps에 확장하려는 시도, multiclass segmentation을 위한 convnet이 있다. Fully convolutional computation은 다수층 신경망에서도 사용되는데 sliding window detection(입력 이미지를 작은 패치로 나누고 각 패치에 대해 CNN을 적용하는 방식), sementic segmentation, image restoration이 있다. 또한 pose estimation을 목적으로 end-to-end 방식의 학습을 진행하는 사례도 있다. Classification의 non-convolutional portion을 제거하고 feature extractor을 만든 사례도 있다. 그들은 proposals(이미지 내에서 객체가 있을 가능성이 있는 영역)과 spatial pyramid pooling을 결합하여 classification을 위한 localized, fixed-length feature을 산출해 낸다. 빠르고 효율적이지만 end-to-end 방식이 아니라는 것이 단점이다. Dense prediction with convnets Convnet을 dense prediction problems에 적용하는 사례들이 존재하는데 semantic segmentation, boundary prediction, image restoration, depth estimation이 그 예이다. 이들을 보통 1. capacity와 receptive fields가 제한되는 작은 모델 2. patchwise training 3. post-processing by superpixel projection, random field regularization, filtering, or local classification 4. input shifting과 output interlacing 5. multi-scale pyramid processing 6. saturating tanh nonlinearities 7. ensembles 를 사용한다. 반면 FCN은 이런 기법들을 사용하지 않는데 실제로 patchwise training, shift-and-stich을 적용해 보았으나 유의미한 성능 개선을 확인하지 못했고 in-network upsampling에 특별한 방법을 사용한다. Deep classification architectures를 확장하고 수정해 image classification으로 supervied pre-training을 진행하고 전체 이미지를 입력으로 하는 fine-tuning을 진행한다. Semantic segmentation을 위해 classification nets를 적용하는 선행 연구가 존재하는 이들은 hybrid proposal-classifier models에만 국한된다. 이들은 R-CNN system을 fine-tune 하여 sematic segmentation, instance segmentation을 수행했다. 하지만 이들은 end-to-end 방식으로 구현하지는 않았다. 하지만 R-CNN을 fine-tuning 한 모델이 PASCAL VOC segmentation과 NYUDv2 segmentation에서 가장 좋은 성능을 보였기에 우리의 end-to-end FCN모델과 성능을 비교해 볼 것이다.
< comment >
Fully convolutional network를 사용하려는 시도와 convnet을 활용하여 dense prediction을 수행하려는 시도는 많았다. 그러나 이 저자들은 자신들만의 구조로 convnet을 재구성하고 end-to-end 방식으로 학습하고 추론하도록 설계했다. 성능은 Section 5에서 확인하게 될 것이다.
3. Fully convolutional networks
< 내용 >
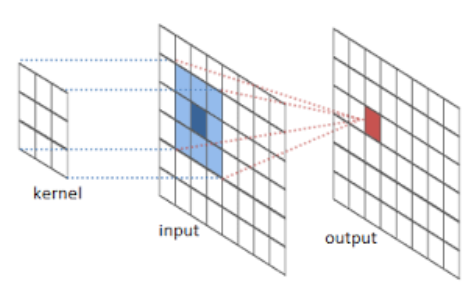
Higher layer의 각 뉴런에 path에 따라 대응되는 이미지의 영역을 receptive fields라 한다.
output의 마지막 빨간 칸에 대응되는 receptive fields는 input의 3*3 정사각형이다.
Convnet은 translation invariance, 이미지 내 객체나 패턴이 변하더라도 모델이 동일한 방식으로 그것을 인식하는 성질을 기반으로 한다. Convnet의 기본 구성 요소인 convolution, pooling, activation funtions는 대응되는 input regions에만 의존하는데 특정 layer의 (i, j) 위치의 data vector를 xij라 하면 그 다음 층의 data vector yij는 다음의 식으로 정의된다.
yij=fks({xsi+δi,sj+δj}0≤δi,δj≤k−1)
여기서 k는 kernel size, s는 stride or subsampling factor, fks는 layer type에 의해 결정되는 함수(a matrix multiplication for convolution or average pooling, a spatial max for max pooling, or and elementwise nonlinearity for an activation function 등등)이다. 이러한 함수식은 합성이 가능한데 합성 시 kernel size와 stride는 다음의 transformation rule을 따른다.
fks∘gk′s′=(f∘g)k′+(k−1)s′,ss′
> 왜 kernel size와 stride에 transformation rule이 위와 같이 적용되냐면 제일 높은 층(층이 높다는 것은 그만큼 층이 입력층으로부터 멀리 떨어졌다는 것을 의미한다.)의 (i, j) 칸을 담당하는 영역은 그다음 높은 층의 (si, sj)부터 (si+(k-1), sj+(k-1))의 k\*k개의 정사각형 영역이고 그중 한 칸인 (si+m, sj+n)을 담당하는 제일 낮은 층의 영역은 (s'si+s'm, s'sj+s'n)부터 (s'si+s'm+(k'-1), s'sj+s'n+(k'-1))의 k'*k'의 정사각형 영역이 된다. 이는 k'*k'의 정사각형 영역이 (s'si, s'sj)부터 (s'si+s'(k-1)+k'-1, s'sj+s'(k-1)+k'-1)인 큰 (s'(k-1)+k')*(s'(k-1)+k') 정사각형 영역을 담당하는 것으로 해석할 수 있게 된다. 따라서 stride의 크기는 ss'이고 커널의 크기는 s'(k-1)+k'이 된다. Gerneral deep net은 FC layer 부분이 존재해 이전 layer와 모두 연결되어 nonlinear function으로 계산하는데 FCN은 오직 conv layer만 존재해 이 layer는 이전 layer와 모두 연결되는 것이 아닌 작은 영역(filter가 지나간 영역)에만 연결되기에 nonliner filter로 계산할 수 있다. 그리고 FCN은 입력의 크기에 제한받지 않고(일반적으로 Convnet은 입력의 크기에 제한받음)그 입력에 대응되는 크기인 output을 형성해 낸다.
> FCN은 입력의 크기가 자유로운 이유?
기존의 convnet은 FC(fully connected) layers가 존재하는데 FC layers는 고정된 수의 뉴런을 가지기 때문이다. FCN은 이 층을 제거했기 때문에 입력의 크기에 대해 자유롭다.
FCN의 손실함수는 final layer의 spatial dimensions의 합인 경우 l(x;θ)=∑ijl′(xij;θ)로 나타낼 수 있다. 여기서 gradient는 각각의 gradient의 합과 같을 것이니 전체 이미지에서 계산된 stochastic gradient descent는 최종 레이어의 수용영역을 미니 배치로 취하여 stochastic gradient descent와 같을 것이다. 따라서, 이렇게 receptive fields가 잘 overlap 되어 있다면, feedfoward computation과 backpropogation이 independently 패치별 계산보다 이미지 전체에 대해 layer별로 계산하는 것이 더 효율적이다. 다음으로 coarse output maps을 만들기 위해 어떻게 classification net을 fully convolutional nets로 변환하는지 소개할 것이다. Pixelwise prediction을 위해 coarse output을 pixel(위치 정보)와 연결시켜야 한다. 3.2에서 소개하는 trick에서 영감을 받아 3.3에서 우리는 upsampling을 위한 deconvolution layers를 소개하고 3.4에선 patchwise training에 대해 이야기해 본 다음, 4.3에서 전체 이미지로 학습하는 것이 빠르고 효율적인지 증거를 들어 살펴볼 것이다.
< comment >
기본적인 Convnet의 성질을 살펴보고 FCN은 nonliner filter를 계산한다는 점, FCN의 loss function은 각 픽셀별 loss function의 합으로 보면 최종 layer의 receptive fields를 미니 배치로 취하여 학습할 수 있다는 점. 그리고 이 분들이 설계하신 구조와 왜 전체 이미지로 학습을 진행하는지에 대해 뒤에서 다룰 것을 말하고 있다.
3.1. Adapting classifiers for dense prediction
< 내용 >
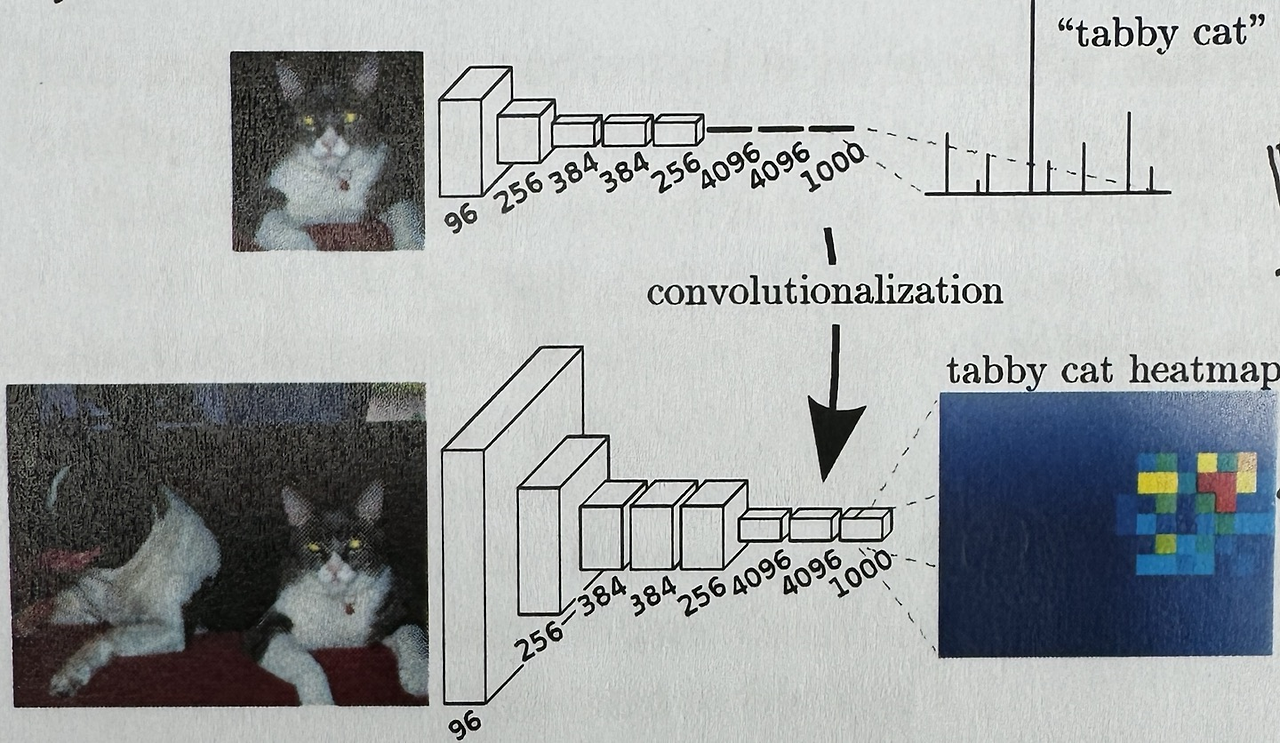
전통적인 recognition nets인 LeNet, AlexNet, 그리고 이들을 더 깊게 구성한 것들은 표면적으로 fixed-sized inputs과 nonspatial outputs(일차원으로 바꾸는 과정이 있다보니..)을 만든다. 이 nets의 fully connected layers는 dimensions가 고정되고 spatial coordinates를 무시하는 단계가 반드시 포함된다. 하지만 fully connected layers는 전체 input regions를 커버하는 하나의 커널로 볼 수 있기 때문에 fully convolutional networks는 input으로 아무 size를 받을 수 있고 output으로 classification maps을 형성할 수 있다.
또한, resulting maps은 네트워크의 특정 입력 패치에 대해 평가한 것과 동등하지만, 계산은 그 패치의 겹치는 영역에 대해 높게 분할된다. 예를 들어 AlexNet은 GPU에서 227*227 이미지 분류 점수를 생성하는데 1.2ms가 걸리는 반면, fully convolutional version은 500*500 이미지에서 10*10 출력 그리드를 생성하는데 0.22ms가 걸린다. 이렇게 convolutionalized models의 spatial output은 sementic segmentation 같은 dense problems에서 사용하기 좋다. 모든 출력 cell에 대해 ground truth가 제공되므로 forward, backward는 직접적이며 convolution의 내재된 연산 역시 효율적이다. AlexNet의 경우 backward times이 2.4ms이지만 fully convolutional 10*10 output을 만드는 데에는 0.37ms의 시간만 걸린다. 이렇게 classification nets를 fully convolutional로 재해석하면 어떤 size의 input에 대해 output maps을 형성할 수 있지만 output의 dimension은 일반적으로 subsampling에 의해 감소하게 된다. Classification nets의 경우 filter를 작게 유지하고 computational requirements를 reasonable 하게 하기 위해 어쩔 수 없이 subsampling을 하니 한 픽셀의 수용영역의 stride만큼 output이 작아 든다.(여기서의 subsampling = downsampling)
< comment >
Classification을 위한 network에서 fully convolutional network 부분만 꺼내온 경우 output은 2차원으로 각 물체의 위치를 표현하게 된다. 하지만 이 output의 성능은 아주 나쁘고 무엇보다 downsampling하면서(pooling layer를 지날 때) output의 크기는 input보다 훨씬 줄어들게 된다. 하지만 계산하는데 걸리는 시간은 classification을 수행하는 데 걸리는 시간보다 훨씬 적게 걸리니 output의 성능을 보안하면서 upsampling 하는 구조를 추가하면 semantic segmentation을 달성하게 된다.
3.2. Shift-and-stich is filter rarefaction
< 내용 >
Input shifting과 output interlacing은 coarse outputs(저해상도 결과물)로부터 dense predictions을 interporlation(보간법, 두 데이터 포인트 사이의 값을 추정하거나 채우는 과정) 없이 수행하는 trick이다. 만약 f배 만큼 downsampling 된다면 left와 top padding으로 x축과 y축에 각각 (0, 1,..., f-1)만큼 움직여 f^2 개수만큼의 이미지를 형성한다. 그런데 이와 같은 효과를(효과가 같지 결과가 같은 것은 아니다.) convnet의 filters와 layer strides만 변화해서 구현할 수 있는데 input stride가 s인 layer를 와 following convolutional layer의 filter weight가 fij라 하자. 만약 lower layer의 input stride가 1이면 lower layer랑 stride가 s인 layer를 지날 때에 비해 s배만큼 upsampling이 된다. 따라서 그 다음 층의 filter 역시 확장해주어야 하고 f′ij={fi/s,j/sif s divides both i and j0otherwise 이를 filter rarefaction이라 한다. 이렇게 filter enlargement를 layer-by-layer로 늘려서 subsampling을 제거해 full net output of trick을 재현한다. 그런데 net안에서 subsampling을 줄이는 것은 trade-off이다. Filter가 finer information을 보게 되지만, receptive fields는 줄어들고 계산하는데 오랜 시간이 걸린다. 사실 shift-and-stich trick에도 다른 trade-off가 존재하는데 filter의 receptive fields를 줄이지 않고 output을 denser 하게 만들 수 있지만 filter가 original design의 finer scale information을 보지 못하게 한다. 우리는 초기에 shift-and-stich로 실험을 진행하였지만 사용하지 않는다는 결론을 내리게 되었고 다음 section에서 말하는 upsampling이 더 효과적이고 효율적인 방법이라 판단하였다. 또한 upsampling이 skip layer와 융합될 때 더욱 효과적이다.
< comment >
보간법을 사용하지 않고 저해상도 결과에서 고해상도 결과를 산출해 내는 Input shifting과 output interlacing에 대해 소개하는 부분이다. 이 방법의 효과를 그저 net에 존재하는 모든 subsampling 요소를 제거하는 방식으로 구현할 수도 있는데 이 분들은 여기 나온 내용의 trick은 효과적이지 않아 사용하지 않는다고 결론 내리셨다. 다음 세션에 나오는 upsampling과 skip layer를 활용하는 게 더 낫다고 결론 내리셨다.
3.3. Upsampling is backwards strided convolution
< 내용 >
Coarse output과 dense pixels를 연결하는 또 다른 방법은 interpolation이다. 예를 들어 가장 simple한 bilinear interpolation은 yij를 가장 가까운 4개의 inputs으로부터 계산한다. 단지 input과 output의 상대적인 위치에만 기반한다. 사실 f 배만큼 upsampling 한다는 것은 input stride를 1/f배만큼 하는 것이랑 같은 의미이다. f가 정수인 한, 자연스러운 upsampling 방법은 output의 stride를 f로 하는 backwards convolution(=deconvolution)이다. 이는 convolution의 방법을 단순히 바꾸면서 구현하게 되는데 그러므로 이 upsampling방식은 in-network에서 pixelwise loss를 줄이는 방향으로 end-to-end learning이 가능하다.(by. backpropagation). 또한 알아야 할 것이 deconvolution filter는 고정될 필요가 없고 학습될 수 있다는 것이다. 이는 네트워크가 데이터로부터 직접적으로 업샘플링 패턴을 배울 수 있다는 것이고 deconvolution layers의 stack과 activation funtions은 nonlinear upsampling을 학습할 수 있다. 우리의 실험에서, 우리는 in-network upsampling이 dense predciton에 대해 빠르고 효과적이라는 결론을 도출하였다. 4.2에서 자세한 구조와 함께 방식을 설명할 예정이다.
< comment >
이 section에서는 FCN에서 쓰이는 upsampling 방식에 대해 소개하고 있는데 바로 deconvolution을 활용한 방법이다. 방식은 convolution을 역으로 수행하면 되고 이 방식의 장점은 end-to-end방식이 가능하다는 점!
3.4. Patchwise training is loss sampling
< 내용 >
우선 loss samplong이란 loss function을 계산할 때 일부 data나 pixel을 무작위로 선정하여 계산하는 방식이다. Stochastic optimization에서 gradient computation은 training distribution(훈련 데이터의 분포)에 영향을 받는다. 학습하는 방식에는 pathwise training(이미지를 패치로 분할 후 학습하는 방식)과 fully-convolutional training(전체 이미지를 한 번에 처리하는 방식)이 있는데 둘 다 어떤 훈련 데이터 분포든 만들 수 있지만 patch의 overlap과 minibatch size(훈련 데이터의 일부)가 computational efficiency에 영향을 받는다. 이 두 방식이 같으려면 각 batch가 이미지의 loss를 측정하는 단위의 모든 receptive fields를 포함하는 경우일 때 같다. uniform sampling of patches보다 효율적인 이 방법(fully-convolutional training인데 이미지 내의 모든 가능한 위치에서 특징을 추출하고 학습하는 것- > patchwise training이 지향하는 것임)은 가능한 batchs의 수를 줄이기 때문에 patch를 랜덤 하게 선택해서 보안한다. 랜덤하게 샘플링된 집합에서 loss를 제한하거나 gradient computation을 수행할 때 특정 patch를 제거할 수도 있다.(DropConnect, 가중치 일부를 무작위로 선택해서 0으로 두어도 됨.) 만약에 patch 간의 overlap이 significant 하면 fully convolutional computation은 속도가 빨라진다. 심지어 backward process의 gradients가 축적된다면 몇 개의 이미지의 patch를 batch에 포함시킬 수도 있다. Patchwise training에서 sampling은 class imbalance를 해결하고 dense pathces 간의 spatial correlation을 완화할 수 있다. Fully convolutional training에선 loss에 가중치를 부여해서 class balance 문제를 해결하고 spatial correlation은 loss sampling을 사용한다. 우리는 실험한 결과(4.3에 나옴) faster or better convergence for dense prediction을 찾을 수 없어 whole image training을 선정하였다.
< comment >
이 절에서는 패치별 훈련 방법과 완전 컨볼루셔널 훈련 방법을 비교한다. 완전 컨벌루션 훈련은 전체 이미지에 효율적이므로 어느 정도 패치별 훈련을 모방하도록 조정할 수 있지만, 패치별 훈련은 클래스 불균형 및 공간 상관 문제를 해결하는 데 유연성을 제공한다. 이 분들은 sampling을 통한 훈련(patchwise training)이 수렴 속도나 품질에 큰 영향을 끼치지 못했다고 판단하여 전체 이미지 훈련을 도입하셨다.
4. Segmentation Architecture
< 내용 >
우리는 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) classifers를 FCN에 적용시키고 이들을 증강하여 in-network upsampling과 pixelwise loss에 대해 dense prediction을 수행하는 모델로 만들었다. Segmentation을 위한 fine-tuning을 진행하였고 새로운 skip architecture을 구성하여 coarse, semantic 정보와 local, appearance 정보를 결합하였다.
이 실험을 진행하기 위해 PASCAL VOC 2011 segmentation challenge 데이터를 사용하였고 per-pixel multinomial logistic loss(cross-extropy loss)와 standard metric인 mix pixel intersection over union(mean IoU)로 훈련시켰다.(background도 하나의 class로 포함시킴.) Ground truth에서 ambiguous하거나 difficul한 pixels은 무시하였다.
< comment >
기존의 classifier을 FCN의 backbone으로 사용하고 skip archictecture을 구성하여 깊은 층의 정보와 얕은 층의 정보를 결합하였다. 이에 대해 알아보자.
4.1. From classifier to dense FCN
< 내용 >
우리는 이미 증명된 AlexNet, VGGnet, GoogleNet을 사용하였다. VGGnet 중 VGG 16-layer net을 사용하였고 GoogLeNet의 경우 final loss layer는 사용하였으며 final average pooling layer는 제거하였다. 모든 nets의 마지막 classification layers는 제거되어 fully connected layers가 convolution layers로 변하였다. 그 후 우리는 1*1 convolution layers를 추가하였는데 filter의 갯수가 4096, 4096, 21개이다. 마지막 층이 21개인 이유는 합성곱층에서 필터의 갯수가 output의 채널 수를 결정하는데 background를 포함한 class의 갯수만큼 채널 수를 생성해 각 class 별 점수로 해석하기 위함이다. 또한 이런 1*1 convolution layer가 3개층으로 이루어져 피처 학습이 효율적으로 이루어지게 하였고 비선형성을 추가하였다.
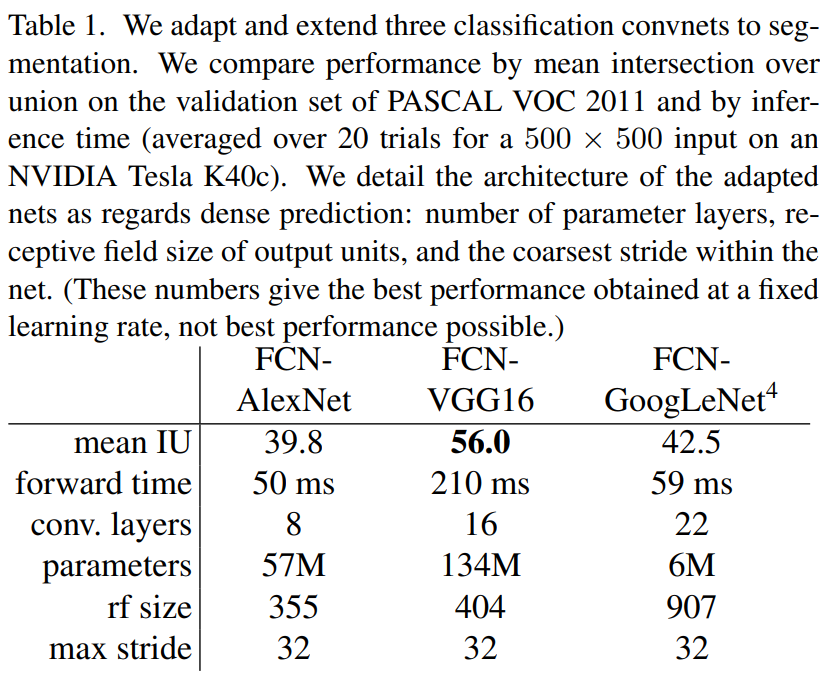
Basic chracteristics를 갖는 net으로 validation을 수행한 결과는 아래 Table 1과 같다.
validation 결과 FCN-VGG16이 가장 좋은 성능을 달성했고 state-of-art를 달성하였다.
< comment >
FCN은 classification에서 우수한 성능을 보인 AlexNet, VGGnet, GoogLeNet의 FC layers를 1*1 layers로 변환해서 segmentation을 수행하였다. 이 층은 학습을 효율적으로 가능하게 하고 특히 마지막 층이 각 class별 점수로 사용된다. 자체 validation의 경우 VGG16이 가장 좋은 성능을 보였고 fine-tuning에 대한 자세한 이야기는 4.3에서 다룰 예정이다.
4.2. Combining what and where
< 내용 >
우리는 segmentation을 위한 새로운 FCN을 정의하여 feature의 계층 구조를 결합하였고 output의 공간적인 정확성을 조정하였다. Fully convolutionalized classifiers는 segmentation을 위해 fine-tune될 수 있어 4.1에서 보인 것처럼 지표면에서 이미 좋은 성능을 보이지만 그 결과물은 만족스럽지 않다.
가장 왼쪽이 그 결과물이다.
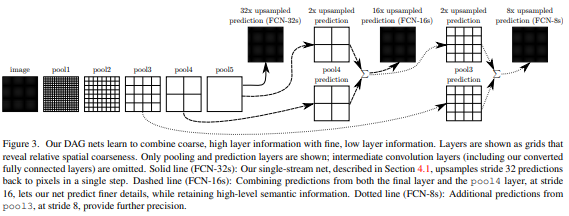
이렇게 final prediction layer가 32 pixel stride를 가진 경우 upsampled output의 detail이 제한받게 된다. 우리는 이 문제를 final prediction layer와 finer strides를 가진 lower layers를 결합하는 방법으로 해결하고자 하였고 이를 DAG의 line topology로 생각하면 lower layers에서 high layer로 skip하는 edge를 만드는 것과 같다.
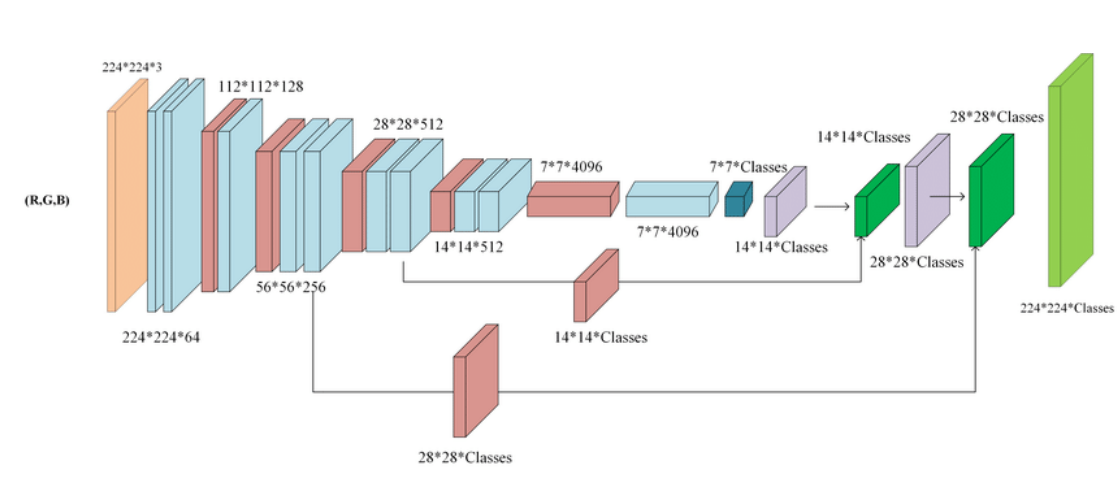
이것이 바로 저자들이 강조한 'skip architecture'이다.
Lower layers는 더 작은 pixels를 보기 때문에, pixel단위로 세밀한 예측을 해야하는 finer scale prediction에 적합하다. 따라서 fine layers의 shallower output과 coarse layers의 output의 결합(단순 시그마)은 global structure을 반영하면서 local prediction을 수행가능하도록 한다. 우리는 이 nonlinear local feature hierachy를 deep jet라고 부른다.
구체적으로 어떻게 수행되냐면 먼저 output의 stride를 반으로 나눠 16 pixel stirde layer에서 prediction을 수행한다. pool4 layer에 1*1 convolution layer를 더해 class prediction을 수행하고 이 결과를 stride가 32인 convolutionalized fc7의 결과에 2배 업샘플링한 결과와 융합시킨다.(이때 단순합을 사용하였는데 max fusion은 기울기가 어떻게 결정되는지 몰라 학습이 어렵기 때문이다.) 초기 업샘플링은 bilinear interpolation을 사용하지만 학습되도록 설계하였다.
이렇게 융합된 결과를 16배 업생플링하는 신경망이 FCN-16s.이다. FCN-16s는 end-to-end 방식으로 학습되고 FCN-32s에도 존재하는 파라미터들의 FCN-32s의 값들로 시작하며 존재하지 않는 파라미터들은 0으로 시작한다. 이 때의 learning rate는 1/100으로 감소한다.
이런 skip net에서의 학습은 validation set에서의 성능을 향상시켜 mean IU를 3을 높인 62.4를 달성했다. Figure 4를 보면 미세한 구조에서도 개선됬음을 확인할 수 있다.
우리는 이러한 융합을 pool3 layer에서도 진행하였으며 이렇게 설계된 신경망은 FCN-8s이다. mean IU는 62.7로 미미하게 상승하였으며 output의 detail과 smoothness가 약간 개선되었다. 이 지점에서 우리는 diminishing returns(들인 시간과 노력 대비 성과가 감소하는 지점)에 도달했다고 파단하여(IU metric, improvement visible) 더 이상 융합을 진행하지 않았다.
Refinement by other means
Finer prediction을 얻기 위한 간단한 방법은 pooling layers의 stride를 감소시키는 것이다. 하지만 우리의 VGG16-based net에서 문제를 당면하게 되는데 pool5의 layer의 stride를 1로 만들기 위해선 convolutionalized fc6가 14*14의 커널 사이즈를 가져야지 이 층의 receptive field size가 유지되기 때문이다. 이는 엄청난 computational cost를 야기했고 사용하지 않았다. 또한 pool5 layer가 더 작은 filters를 갖도록 모델 구조를 변형해 보았지만 성공적인 성과를 가져오지 못했다. 이는 ImageNet-trained weights가 변형된 구조에서는 적합하지 않기 때문에 인 것 같다.
또다른 방식으로 finer prediction을 얻는 방법에는 shift-and-stich 방법이 있다. 제한적인 실험환경에서 우리는 cost to improvemnet ratio가 기존 layer fusion 방식보다 낮다 판단하였다.
< comment >
딥러닝 모델의 중간 산물을 upsampling할 때 사용한다는 발상이 주목할 만하다. Stride가 작은 layer일 수록 위치에 대한 정보를 잘 갖고 있으니 분류를 하는 층의 정보와 이 층의 정보를 융합한다는 발상은 매우 타당하다. 그 결과 저자들의 수치적인 향상 뿐만아니라 detatil 측면(output의 결과물)에서도 향상을 얻게 되었다.(mean IU로는 전체적인 성능을 나타낼 뿐 detail한 부분에 대한 지표로는 적합하지 않다.)
4.3. From classifier to dense FCN
< 내용 >
Optimization
우리는 모멘텀이 있는 SGD로 훈련하였고 미니배치 사이즈는 20개의 이미지, learning rate는 10^-3, 10^-4, 5^-5로 각각 FCN-AlexNet, FCN-VGG16, FCN-GoogLeNet에 사용하였다. 모멘텀은 0.9를 사용했으며 weight decay는 5^-4 혹은 2^-4를 사용했고 biases의 learning rate는 두배 하였다.
우리는 class scoring convolution layer를 zero로 시작하였고 dropout은 기존 classifier nets에 존재하는 부분에만 사용하였다.
Fine-tuning
우리는 전체 layer를 backpropagation을 통해 fine-tuning하였다. Output classifier만 fine-tuning한 것은 전체를 fine-tuning한 것에 비해 70%의 성능을 보였다. 처음부터 학습하는 것은 base classification nets를 학습하는데 많은 시간이 소요되어 합리적이지 않았다. Single GPU를 사용해서 FCN-32s를 fine-tuning하는데 3일이 걸렸고 FCN-16s, FCN-8s로 upgrade하는데 각각 하루가 더 소요되었다.
Patch Sampling
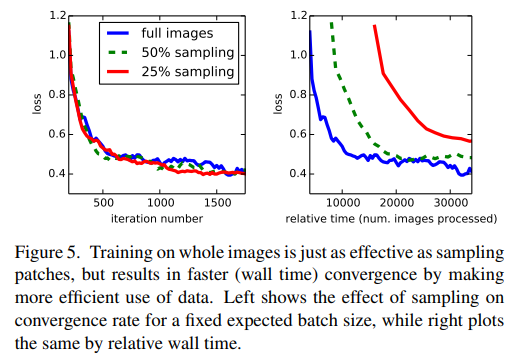
우리의 full image training은 각각의 이미지를 크고 겹치는 패치의 규칙된 격자에 배치하였다. 반대로 이전의 작업들은 전체 dataset에서 patches를 random하게 sampling 하였는데 이는 잠재적으로 배치에 높은 variance를 부여하여 convergence를 가속화한다고 알려져있기 때문이다. 우리는 이를 마지막 층의 cell을 p만큼 선택하는 방식으로 설계했는데 효과적인 batch size가 변하는 것을 막기 위해 batch당 image의 갯수를 1/p배 만큼 늘렸다. 이런 rejection samplin 방식은 patchwise training보다 더 빠른 속도를 보였다.
위 그래프는 여러 방식의 convergence를 보여주는데 우리는 sampling이 whole image training에 비하여 significant effect가 존재하지 않다고 판단하였다.(왼쪽 그래프) 반면 오른쪽 그래프를 보면 sampling한 경우 배치당 더 많은 이미지를 고려하기 때문에 relative time은 더 느리게 관측되었고 따라서 우리는 whole image training을 사용하게 되었다.
Class Balancing
Fully convolutional training은 weighting loss or sampling loss의 방법으로 classes를 balancing할 수 있는데 우리의 레이블은 약간 불균형되어 있어도 class balancing은 불필요하다고 여겼다.
Dense Prediction
Deconvolution layer를 지나면서 upsample되고 dense prediction을 수행하였는데 마지막 층의 deconvolution filters만 bilinear interpolation으로 고정되고 나머지는 초기에 bilinear upsampling으로 시작하였으나 학습되도록 설계하였다. Shift-and-stich, filter rarefaction equivalent들은 사용되지 않았다.
Augmentation
우리는 randomly mirroring과 jittering(jittering은 이미지의 색상, 밝기, 대비 등을 약간 변형시키거나 이미지를 약간 회전시키고, 크기를 조절하는 등의 방법으로 데이터의 다양성을 증가시키기 위해 사용됨)을 사용했지만 주목할만한 향상은 없었다.
More Training Data
Table 1에 사용한 PASCAL VOC 2011 trainign set은 1112 images이고 이외에도 8498 PASCAL training images는 모델의 성능 향상을 불러왔다.
Implementation
모든 모델들은 Caffe에서 학습되었고 NVIDIA Tesla K40c를 사용하였다. 모델과 코드는 오픈 소스로 공개되어있다.
< comment >
FCN의 나머지 자잘한 부분들이 어떻게 설계되어있는지 알려주고 있다. SGD with momentum, transfer learning, whole image training을 사용하였다.
5. Results
< 내용 >
우리는 FCN을 sementic segmentation과 scene parsing에 훈련하였다.
먼저 metrics를 소개하자면
이고 다음은 데이터셋마다 비교한 결과를 첨부하겠다.
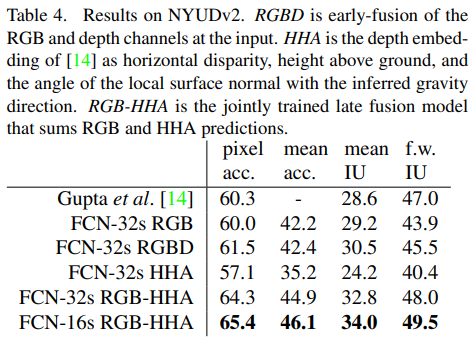
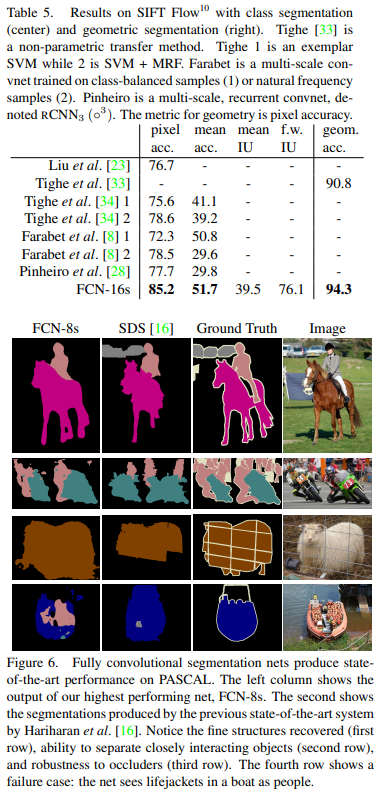
< comment >
사실 결과는 그렇게 중요한 부분이 아니라(대부분 논문에선 자신의 model이 sota model이다. 아무래도) 그냥 논문 캡처한 것으로 대체하겠다.
6. Conclusion
< 내용 >
Fully convolutional networks는 현대의 classification convnets을 special하게 바꾼 case이다. Classification을 segmentation으로 확장하고 multi-resolution layer를 탑재한 개선된 모델 구조는 learning과 inferfence의 속도는 빠르게 했으며 성능상으로 state-of-the-art를 달성했다.
< comment >
FCN에서 사용한 주요 techniques는 fully convolution layers, up-sampling by deconvolution, skip architecture가 되겠다.
7. 느낀점
논문 리뷰를 자세히 하려는 마음때문에 하나 하나 포스트 올리는데 오랜 시간이 걸리지만 천천히 하나씩 올려보도록 하겠다. 다음은 FCN을 사용해 cloth segmentation을 해볼 것이다.