이번엔 Diffusion Model 중 하나인 DDPM에 대해 알아보자.
2. MLDL2 수업 - Diffusion Models

**무단 배포 금지** 본 게시물의 저작권은 김태섭 교수님께 있습니다.
1. VAE to Diffusion Models
사실 교수님께서 diffusion을 알기 위해선 VAE가 필수라고 하셔서 VAE를 짚고 넘어가는 거긴함.
Diffusion 출발은 저번 포스트의 마지막인 Hierachical Variational Auto-Encoder(HVAE)이다.(이말이 꼭 HVAE를 기반으로 diffusion이 만들었다는 말은 아니고 이해하는 관점에서 HVAE와 비교하면서 보는 것이 타당하다.)
HVAE는 VAE를 generalize한 모델이다. 기존에 VAE에선 latent variable이 하나였지만 이 variables를 늘리고 이 들을 hierachical하게 설계하여 일반화한 것이다. Hierachical하게 설계했다는 것은 latent variable사이 순서, 계층 구조가 있음을 의미한다. 따라서 latent variable역시 더 높은 level = 더 abstract한 latent variable로부터 생성된다.
HVAE에선 abstract할 수록, higher-level로 갈수록 그 크기가 줄어든다. = compact해진다.(encoder에서 출력하는 다음 층의 평균과 분산이 계속 줄어드는 것)
그리고 joint-distribution에 하나의 성질이 있는데 markov property이다. 즉, 다음 요소를 결정하는 것은 바로 이전의 요소만이라는 것.(만약 이 성질이 없다면 저 수많은 latent variable로부터 계산할 수 없을 것이다..)
마찬가지로 HVAE에서의 encoder는 x로부터 low-level, high-level의 z를 만들어내고
이 역시 markov property를 가지며 이 q(z_{1:T}|x)는 p(z_{1:T}|x)를 추정하는 분포이다.
HVAE에서 evidence를 써보면 다음과 같이 전개되는데
ELBO에 위 두 그림에서 얻은 식을 넣으면 최종 식이 나오게 된다.
2. Denoising Diffusion Probabilistic Models(DDPM)
DDPM은 diffusion model의 초기 model로 VAE에 추가적인 3가지 restrictions를 넣는다.
(수업 자료에는 VDM으로 명시하였는데 나는 틀렸다고 생각한다. VDM은 DDPM과 VAE를 결합한 것이기 때문에 잠재 공간에 대한 이야기가 다루어져야 하는데 전혀 다루지 않기 때문이다. 생각해보면 이런 제약을 넣는 것 자체가 더 기초적인 모델임을 의미한다. 즉 VDM은 아래에서 설명하는 첫번째 제약이 없어지기 때문에 잠재 공간에 대한 자유성이 부여되는 한 단계 더 발전한 모델인 것이다. 더 공부해보고 혹시 내 생각이 틀렸다면 수정하겠다.)
(VAE와 DDPM의 공통점은 간단한 분포로 근사해서 생각하는 variational inference, VI를 한다는 것인데 다루는 공간이 각각 latent space, data space자체를 다루는 것이 차이이다.)
첫번째가 latent variable의 size와 input data의 size가 갖다는 것인데 위의 HVAE에서 higher-level일수록 compact해진다는 특성이 있지만 VDM에서는 모든 latent variable과 input의 size가 같다.
두번째는 encoder는 학습되지 않고 pre-defined된 linear Gaussian Model를 사용한다.
여기서 알파는 hyperparameter이다.
세번째로 위 gaussian parameters인 알파가 위치에 따라(t로 표현해 시간에 따라가 맞는 표현일 수 있다.) 다르고 마지막 latent variabel x_{T}의 분포는 standard Gaussian N(0,I)이라는 것이다.
그럼 forward diffusion process는
이 식을 통해 진행되며 이미지에 noise가 첨가되기 때문에
encoding 과정을 noising이라고도 부른다.
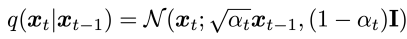
+ 왜 정규분포가 저렇게 생겼는가?
일단 정규분포를 사용하는 이유는 정규분포를 다르는 noise를 넣기 위함이고 그럼 위 식에 의해
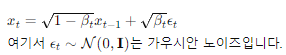
이렇게 다음 단계의 latent variable이 생성된다.(VAE에서 reparameterization trick과 동일한데 사실 꼭 이 방법을 사용하지 않아도 된다. 미분 가능하면서 sampling과 같은 효과를 내는 방식이 또 있다는 뜻) 이 때 앞 계수들의 의해 x_{t}의 분산이 x_{t-1}과 같아지게 된다.
반대로 reverse denoising process는 생성하는 과정으로


이 과정을 아래의 식으로 하기 때문에
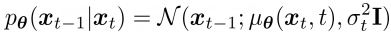
평균과 분산을 출력할 network 학습이 필요하다.
정리해보면

이러한 과정이고
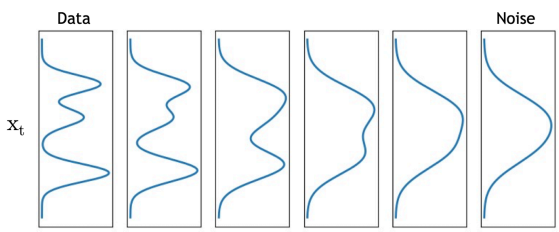
원 data로 부터 잠재변수의 분포를 추론해가는 과정으로 볼 수 있다.

이번엔 DDPM에서 ELBO을 살펴보자.

Jensen's Inequality를 사용하였고 식을 더 전개하면

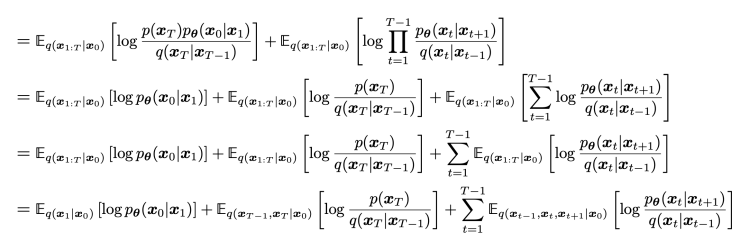
마지막 식은 markov property로 확률을 대체하고 의미없는 변수들을 다 적분해버리면 나오게 된다. 그럼 이 식은
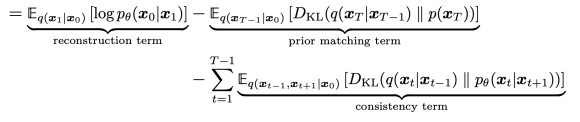
이런 세가지 term이 되는데
먼저 reconsturction term은 VAE와 동일하고
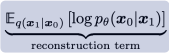

그 다음 prior matching term은

두번째 제약 조건에 의해 encoder는 아래 분포로 고정되고

세번째 제약 조건에 의해 마지막 잠재변수의 분포는

이기 때문에 학습되는 파라미터가 없다. 즉, constant이다.

마지막 consistency term은

디코더의 분포와 인코더의 분포의 차이의 기대값을 모든 항에 대해 계산하는 term으로 의미적으론 reverse process를 forward process에 맞추는 term이다. 그러나 이 term의 Monte Carlo estimate(확률론적 방법을 사용하여 기댓값이나 적분을 계산하는 방식, 주로 random sampling을 사용한다.)는 두 개의 변수를 매 time steps마다 다루기 때문에 높은 variance를 야기한다. 따라서 이를 해결하기 위해 한 step마다 하나의 변수에 대한 기댓값을 구하도록 바꿔어야 한다.
이는 생각보다 간단하게 해결되는데 markov property로 식을 변형하면 해결된다.

encoder의 변분 분포를 이렇게 바꿔주면

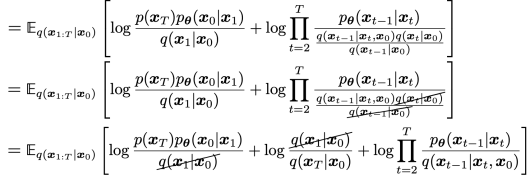
log내에 곱으로 되어 있는 항들이 cancellation이 일어나게 된다.

그럼 최종식은
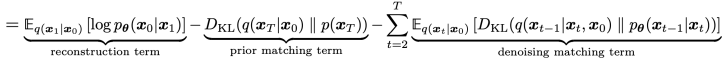
이렇게 되어

consistency term이 denoising matching term으로 바뀐 것을 알 수 있다.
Denoising matching term을 좀 더 자세히 살펴보면 왼쪽 식은 encdoer에서 만든 denoising ground-truth signal인데

이렇게 표현된다. 이 수식이 참 만만치 않은데 x_t를 reparameterization으로 구했다 가정하고 접근해보겠다.

이 수식에서 이상한 부분이라면

이 부분인데 쉬운 말로 '정규분포는 정규분포를 낳는다.'라는 말에서 유래한 것이다. 자세한 수식은 잡지식에 올려두겠다.
(왜 정규분포는 정규분포를 낳을까?)
2024.05.31 - [다양한 분야의 잡지식] - 말 그대로 다양한 분야의 잡지식
말 그대로 다양한 분야의 잡지식
여기는 말 그대로 다양한 분야의 잡지식을 기록하고 싶을 때 사용하는 공간입니다. Ctrl+F해서 원하는 지식을 찾을거임.Time Series1. EMA(Exponential Moving Average)Computer Vision1. 필터와 커널의 차이- 필터
go-big-or-go-home.tistory.com

그럼 이 과정을 확장하여

에 도달하고 추가로 쓰였던 성질의 함수를 전개하면




다시 돌아와서 denoising matching term은

decoder와 ecoder 사이의 차이를 최소화하는 term이다. 그런데 두 정규분포 사이의 KL divergence는 비교적 쉽게 계산되는데
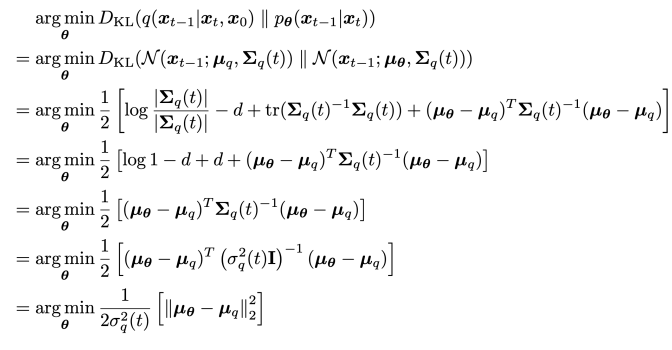
이므로 세타를 최적화 하는 것은 결국 생성 과정의 뮤세타가 인코더의 뮤큐와 같게하는 것이다. 따라서 뮤세타를 뮤큐와 같은 형태로 설계하는 것이 자연스럽고 T시점부터 출발하기 때문에 모르는 x_0를 각 층마다 예측하게 되는 것이다. 이렇게 정한 뮤세타와 뮤큐를 다시 대입하면

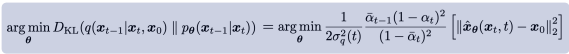
이러한 결론에 도달한다.
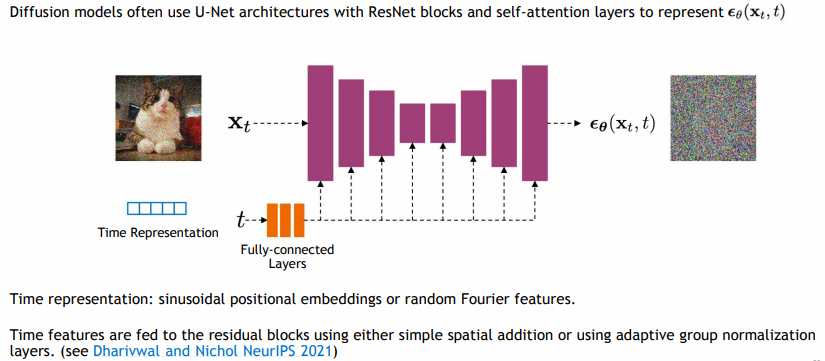
DDPM에서는 다른 추가적인 FC layers와 U-Net architecture를 둬서 t시점의 x_0를 예측한다.

위 그림에 표현되지는 않았지만 skip connections(고해상도의 이미지를 저해상도에 전달하는 것)가 있고 이 과정은 매 time마다 진행된다.
그런데 여기서 DDPM을 더 개선한 방식이 있는데

x_0를 마치 x_t와 노이즈의 결합으로 해석하는 방식이다. 그럼 예측한 뮤세타 역시

이런 꼴로 바뀌게 되고 목적함수는
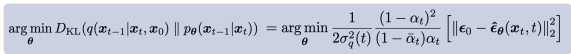
noise에 대한 식으로 바뀌게 된다.

이렇게 노이즈를 예측하는 방식이 주로 쓰인다고 하는데 그 이유는 노이즈 예측 방식이 더 안정적이고, 학습 과정에서 더 좋은 성능을 보이는 것으로 나타났기 때문이다.
추가로 DDPM을 응용하는 것으로 주어진 conditions하에서 generate하는 방식이 있는데 encoder는 fix하고
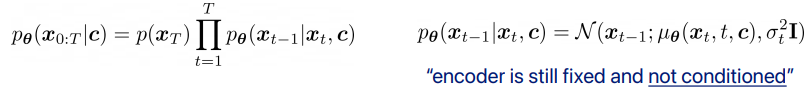
이미지를 generate하는 방식에서 조건 이미지를 추가로 넣어 U-Net 구조를 학습시킨다.

그럼 이렇게 훈련된 모델은 각각 새로운 이미지에 대해 해상도를 복원할 수 있고 색체화가 가능하다.
마지막으로 여러 generative models를 비교해보면
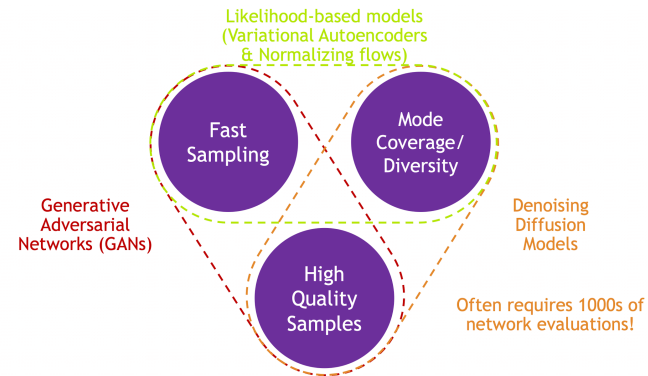
Diffusion Models는 아무래도 time의 길이가 길어 fast sampling은 힘들지만 high quality와 diversity한 sample을 만든다는 강점이 있다.
3. 마무리
이번 포스트에선 diffusion의 가장 간단한 모델인 DDPM을 알아보았다. 이제 preview 영상으로 가봅시다.
3. Preview 영상
스터디가기 전에 보기로한 영상에 대해 정리해보겠다.
Diffusion Model 수학이 포함된 tutorial (youtube.com)
읽어보니까 꽤나 DDPM을 이 post에서 깊게 다루어서 생각보다 흐름을 이해하는데는 어렵지 않았다. Preview 영상이니 자세한 수식보단 큰 흐름과 위에 없는 내용 위주로 요약하겠다.
- Denoising Diffusion Models는 두 과정으로 이루어진다.:
- Foward diffusion process -> noising
- Reverse denoising precess -> denoising


- 이렇게 알파 바를 잡았던 것이 특정 시점의 x를 한번에 예측하기 위해서였다.

- intractable은 다루기 어려움을 의미한다.

- ELBO 대신 variational upper boudn로 loss를 정의한다.

- noise만으로도 예측 가

- diffusion은 weighting을 equally하게 적용하지만 advanced weighting도 있다.

- Time representation에 사용되는 것으로 sinusoidal positional embeddings(트랜스포머에서 쓰임)와 random Fourier features가 있다.
- DDPM은 reverse의 시그마 t를 베타 t로 두지만 이 역시 학습가능하다.

- T가 작을수록 high-frequency content = low-level details를 생성한다.

- DDIM: 마르코브 property가 아닌 x_0가 모든 x에 영향을 준다.(Non-Markovian diffusion process)

- Score-based Generative Modeling with Differential Equations

SDE 하에서 score-based model과 diffusion이 사실 같다는 놀라운 사실
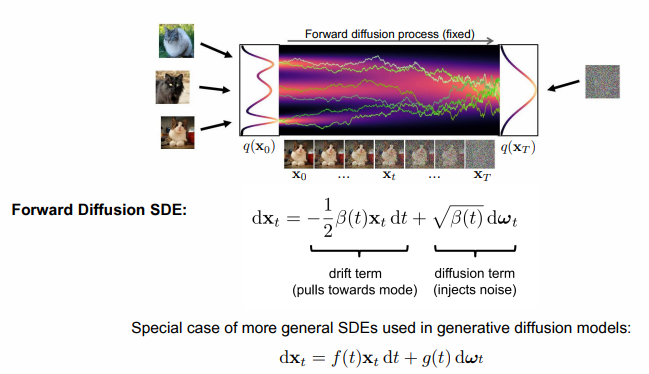

수식이 꽤나 어려워보인다.

- 좀 더 deterministic한 모델

- 특정 조건하에서 생성하는 모델

- 새로운 classifier를 도입하여 구현하는 방식

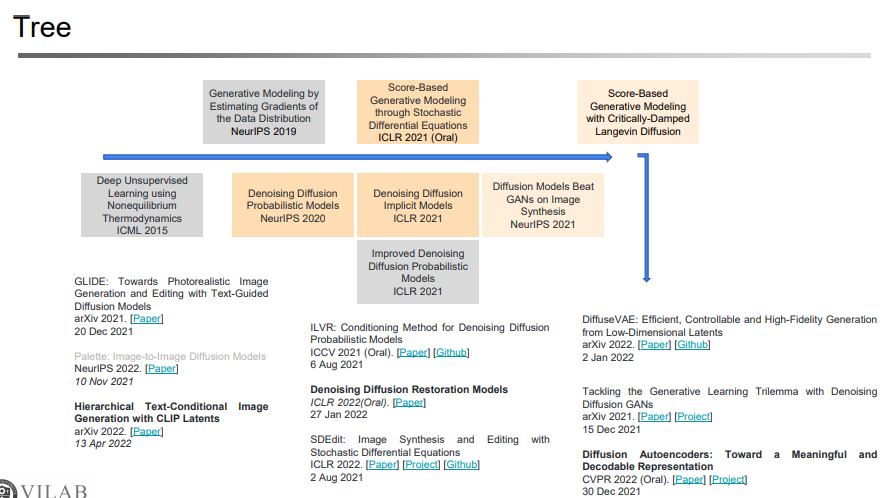
- 마지막으로 직접 만드신 tree
'DL > Generative Model' 카테고리의 다른 글
| [Paper Review] Denoising Diffusion Implicit Models (0) | 2024.07.24 |
|---|---|
| CT-GAN, TVAE + CTAB-GAN, CTAB-GAN+ (0) | 2024.07.21 |
| [Paper Review] Denoising Diffusion Probabilistic Models (0) | 2024.07.16 |
| [Paper Review] Auto-Encoding Variational Bayes - VAE (0) | 2024.07.10 |
| [Generative Model 스터디] 1주차-1(VAE) (0) | 2024.07.01 |