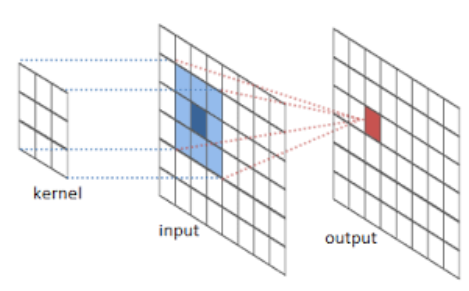
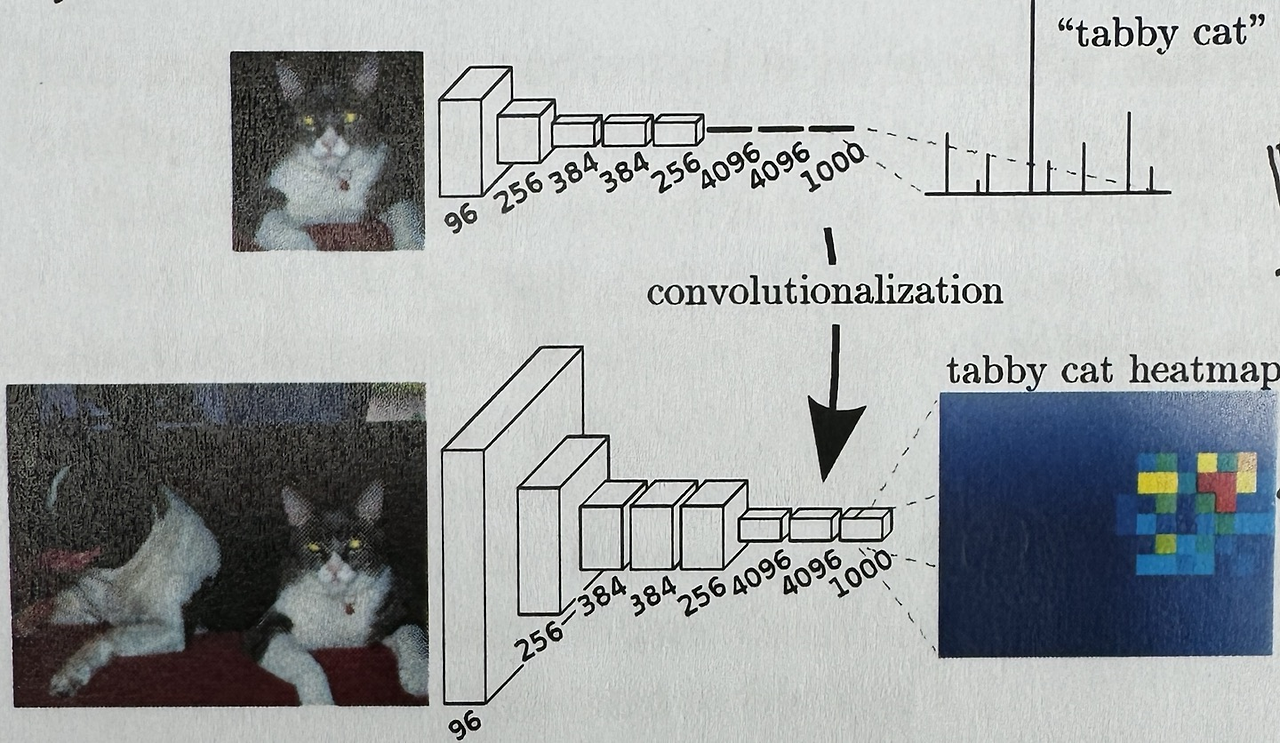
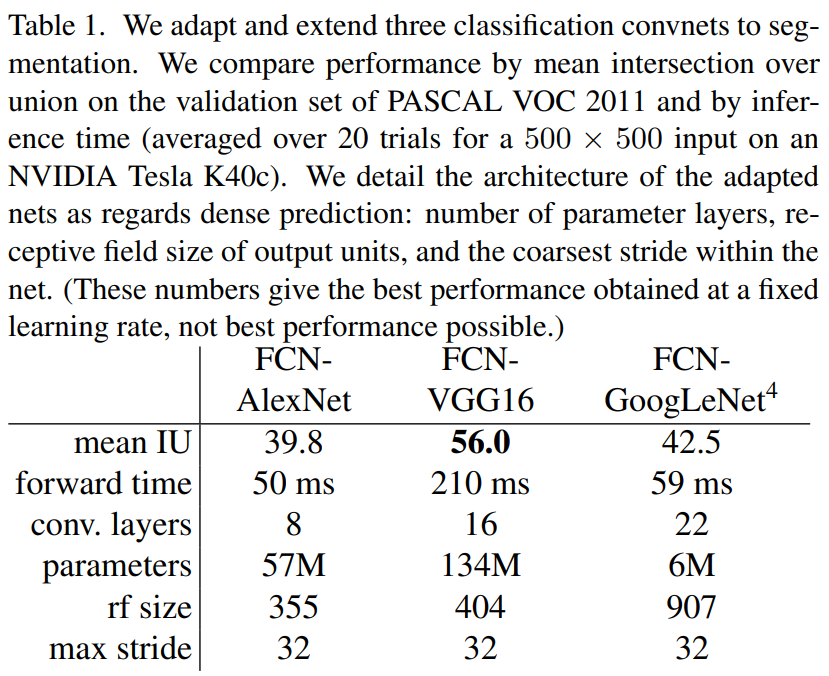
오늘을 FCN을 pytorch로 구현해보고 cloth segmentation을 수행해보겠다.

1. 데이터셋 준비
다시 root 디렉터로리로 돌아오고

zip 파일을 풀어주겠다.

데이터 셋은 https://www.kaggle.com/datasets/rajkumarl/people-clothing-segmentation/data서 다운받았다.
People Clothing Segmentation
Outdoor Images of People and Semantic Segmentation Masks of Their Clothing
www.kaggle.com
이제 train셋과 validation셋을 구분지어야 하는데
# 원본 이미지 및 마스크 경로
images_src_dir = './png_images/IMAGES'
masks_src_dir = './png_masks/MASKS'
# 타겟 디렉토리 설정
train_images_dir = 'dataset/train/images'
train_masks_dir = 'dataset/train/masks'
val_images_dir = 'dataset/val/images'
val_masks_dir = 'dataset/val/masks'
# 타겟 디렉토리가 존재하지 않으면 생성
os.makedirs(train_images_dir, exist_ok=True)
os.makedirs(train_masks_dir, exist_ok=True)
os.makedirs(val_images_dir, exist_ok=True)
os.makedirs(val_masks_dir, exist_ok=True)
# 원본 이미지 디렉토리의 모든 파일 목록 가져오기
all_images = os.listdir(images_src_dir)
# 이미지를 랜덤하게 섞기
random.shuffle(all_images)
# 검증셋과 훈련셋으로 나누기
val_images = all_images[:100]
train_images = all_images[100:]
# 이미지와 매칭되는 마스크 파일 복사
for img_name in val_images:
# 이미지 파일 복사
shutil.copy(os.path.join(images_src_dir, img_name), os.path.join(val_images_dir, img_name))
mask_name = img_name.replace('img', 'seg')
shutil.copy(os.path.join(masks_src_dir, mask_name), os.path.join(val_masks_dir, mask_name))
for img_name in train_images:
# 이미지 파일 복사
shutil.copy(os.path.join(images_src_dir, img_name), os.path.join(train_images_dir, img_name))
mask_name = img_name.replace('img', 'seg')
shutil.copy(os.path.join(masks_src_dir, mask_name), os.path.join(train_masks_dir, mask_name))
print("이미지와 마스크 파일의 분할이 완료되었습니다.")
전체가 1000장이어서 100장을 validation set에 넣었고 이미지 파일을 복사하기 위해서 shutil이라는 메서드를 사용하였다.
이 과정의 프로세스만 이야기하면 이미지가 전체 들어있는 디렉토리에 속해이는 모든 파일을 all_images에 가져오고, random.shuffle()을 통해 이를 랜덤하게 섞은 다음 그 중 앞에 있는 100개를 val_images에 분류하였다. 그 후 os.path.join()과 shutil.copy(a, b)를 통해 a의 이미지를 복사하여 b에 붙여넣었다. 그 후 파일명을 확인했을 때 image와 mask의 차이가 img과 seg로 되어 있어(뒷부분은 동일) 이렇게 replace하고 mask도 저장해주었다.
이 결과
dataset
- train --images
--masks
-val -- images
-- masks
로 저장되었다.
이번엔 데이터 로더에 데이터를 로드해볼 것인데
class SegmentationDataset(Dataset):
def __init__(self, images_dir, masks_dir, transform=None, target_transform=None):
self.images_dir = images_dir
self.masks_dir = masks_dir
self.transform = transform
self.target_transform = target_transform
self.images = sorted(os.listdir(images_dir))
self.masks = sorted(os.listdir(masks_dir))
self.images = [img for img in self.images if os.path.isfile(os.path.join(images_dir, img))]
self.masks = [msk for msk in self.masks if os.path.isfile(os.path.join(masks_dir, msk))]
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.images_dir, self.images[idx])
mask_path = os.path.join(self.masks_dir, self.masks[idx])
image = Image.open(img_path).convert('RGB')
mask = Image.open(mask_path).convert('L')
if self.transform:
image = self.transform(image)
if self.target_transform:
mask = self.target_transform(mask)
mask = torch.tensor(np.array(mask), dtype=torch.float32).unsqueeze(0)
return image, mask
# 데이터 전처리
# resize, to tensor, normalization
# 이외에도 centor crop. gr# 이외에도 centor crop. grapyscale, random affine transformations
# 이외에도 centor crop. grapyscale, random affine transformations
# random crop, ramdom horizontal flip, color jitter, 등의 방법이 있음.
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
target_transform = transforms.Compose([
transforms.Resize((256, 256)),
# transforms.ToTensor(),
])
train_images_dir = './dataset/train/images'
train_masks_dir = './dataset/train/masks'
val_images_dir = './dataset/val/images'
val_masks_dir = './dataset/val/masks'
train_dataset = SegmentationDataset(train_images_dir, train_masks_dir, transform=transform, target_transform=target_transform)
val_dataset = SegmentationDataset(val_images_dir, val_masks_dir, transform=transform, target_transform=target_transform)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False)이렇게 SegmentationDataset이라는 class를 정의하고 Dataset 클래스를 상속받는 class에서 정의하는 __len__함수와 __getitem__함수를 정의해주었다. Dataset의 masks는 gray scale이고 각 픽셀의 값이 class를 의미하기 때문에 .convert('L')을 해주었고 images는 .convert('RGB)를 해주었다. 이후 images와 masks 각각에 적절한 데이터 전처리를 해주었는데 공통은 Resize((256, 256))이고(사실 안해주어도 구현이 가능하나 계산의 용이성을 위해 처리하였다.) images는 ToTensor()와 Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])를 mask에는 torch.tensor(np.array(mask), dtype=torch.float32).unsqueeze(0)를 적용해주었는데 그 이유는 segmentation에서는 대부분 mask의 각 값이 class를 의미하기 때문에(gray scale인 경우 더 그럴 확률이 높다.) Normalize를 하지 않고 그 값을 보존해야 했기 때문이다. 파이토치의 transforms.ToTensor()은 0~1사이로 scale하는 과정이 포함되기 때문에 이 방법이 아닌 torch.tensor(np.array(mask), dtype=torch.float32).unsqueeze(0)을 사용하였다. 이후 DataLodaer함수를 통해 train_loader와 val_loader에 batch_size=8로 데이터를 로드해주었다.
+
self.images = [img for img in self.images if os.path.isfile(os.path.join(images_dir, img))]
self.masks = [msk for msk in self.masks if os.path.isfile(os.path.join(masks_dir, msk))]이 부분은 jupyter notebook이 자체적으로 안보이는 ipynb 파일을 생성해서 필터링해주는 부분이다.
++
마스크의 데이터가 어떻게 생겼는지 확인하기 위해 masks.max().item()을 출력하면 다음과 같다.
# Mask 범위 확인
for images, masks in train_loader:
max_value = masks.max().item()
print(f'Max value in masks: {max_value}')
break # 첫 번째 배치의 최댓값만 확인하기 위해 반복문 종료Max value in masks: 54.0모델을 정의하기전 데이터를 시각화 해보겠다.
정규화가 진행되었기 때문에 정규화를 역변환하는 함수를 정의하고 시각화 하는 함수를 정의한 다음 첫번째 배치의 5번 index를 시각화 해보았다.
## 데이터 시각화
# 정규화 역변환 함수
def denormalize(image_tensor, mean, std):
mean = np.array(mean)
std = np.array(std)
image = image_tensor.permute(1, 2, 0).cpu().numpy() # CHW -> HWC
image = std * image + mean # 정규화 역변환
# clipping: 0보다 작으면 0, 1보다 크면 1로 변환
# 값이 비정상적으로 크거나 작아지는 것을 방지하는 역할
image = np.clip(image, 0, 1) # [0, 1] 범위로 클리핑
# 이미지 시각화 라이브러리(OpecV, matplotlib 등)은 이미지 데이터를 0에서 255 범위의
# 8비트 정수 형태로 다루기 때문에 정규화된 [0,1] [0,255]로 변환
image = (image * 255).astype(np.uint8) # [0, 1] -> [0, 255]
return image
def imshow(image_tensor, mask_tensor, mean, std):
image = denormalize(image_tensor, mean, std) # 정규화 역변환 적용
# 채널 차원 제거, cpu로 이동, numpy 배열로 변환
mask = mask_tensor.squeeze(0).cpu().numpy()
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title('Image')
plt.axis('off')
plt.subplot(1, 2, 2)
# color map을 지정하는 인자, 그레이스케일 컬러 맵을 사용하여 이미지를 시각화함.
plt.imshow(mask, cmap='gray')
plt.title('Mask')
plt.axis('off')
plt.show()
# 데이터셋에서 배치 하나를 로드하여 시각화
# 데이터 로더는 각 배치를 (input, target) 형태로 반환함.
# iter는 데이터로더 객체에 대한 이터레이터를 생성해 순차적으로 배치를 가져오게 함
# next는 이터레이터에서 다음 배치를 가져옴.
images, masks = next(iter(train_loader))
print("배치의 크기:",images.size())
print("이미지의 크기:",images[0].size())
# 정규화 역변환에 필요한 mean과 std -> ImageNet dataset에서 생성됨.
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# 첫 번째 이미지와 마스크 시각화
imshow(images[5], masks[5], mean, std)matplotlib.pyplot의 imshow는 단일 채널의 경우 2D 배열, 단일 채널이 아니라면 3D 배열을 입력 받고 마지막 차원을 채널로 인식하기 때문에 RGB 채널인 image는 permute(1,2,0)을 통해 CHW 차원을 H,W,C 순서로 바꿔주었고 mask는 C 차원을 없애 주었다. 또한 scaling을 image에서만 했기 대문에 image = np.clip(image, 0, 1)과 image = (image*255).astype(np.unit8)을 통해 matplotlib가 원하는 0부터 255사이의 8비트 정수 형태로 만들어주었다.
이후 plt.subplot()을 통해 왼쪽에는 이미지, 오른쪽에는 mask를 시각화하였다.

2. 모델 정의
그 다음은 저번 논문을 토대로 FCN8s의 class를 정의해보았다.
class FCN8s(nn.Module):
def __init__(self, n_class, learned_bilinear=True):
super().__init__()
self.n_class = n_class
self.learned_bilinear = learned_bilinear
self.loss = torch.nn.CrossEntropyLoss(reduction='sum')
# Conv2d: 입력 채널수, 출력 채널수, 커널 사이즈 -> 스트라이드 기본값 1
# (입력크기+2*패딩-커널크기)/스트라이드+1
# Sequential은 여러 신경망 계층을 모듈로 구성하여 순차적으로 연결할 수 있기 위해 사용용
# MaxPool2d: 필터의 크기, 필터가 이동할 간격, ceil_mode=True -> 출력 크기 계산시 올림 사용하도록
self.conv_block1 = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=100), # 입력: (3, 224, 224), 출력: (64, 422, 422)
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 3, padding=1), # 입력: (64, 422, 422), 출력: (64, 422, 422)
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True) # 입력: (64, 422, 422), 출력: (64, 211, 211)
)
self.conv_block2 = nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1), # 입력: (64, 211, 211), 출력: (128, 211, 211)
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, 3, padding=1), # 입력: (128, 211, 211), 출력: (128, 211, 211)
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True) # 입력: (128, 211, 211), 출력: (128, 106, 106)
)
self.conv_block3 = nn.Sequential(
nn.Conv2d(128, 256, 3, padding=1), # 입력: (128, 106, 106), 출력: (256, 106, 106)
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1), # 입력: (256, 106, 106), 출력: (256, 106, 106)
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1), # 입력: (256, 106, 106), 출력: (256, 106, 106)
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True) # 입력: (256, 106, 106), 출력: (256, 53, 53)
)
self.conv_block4 = nn.Sequential(
nn.Conv2d(256, 512, 3, padding=1), # 입력: (256, 53, 53), 출력: (512, 53, 53)
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1), # 입력: (512, 53, 53), 출력: (512, 53, 53)
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1), # 입력: (512, 53, 53), 출력: (512, 53, 53)
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True) # 입력: (512, 53, 53), 출력: (512, 27, 27)
)
self.conv_block5 = nn.Sequential(
nn.Conv2d(512, 512, 3, padding=1), # 입력: (512, 27, 27), 출력: (512, 27, 27)
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1), # 입력: (512, 27, 27), 출력: (512, 27, 27)
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1), # 입력: (512, 27, 27), 출력: (512, 27, 27)
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True) # 입력: (512, 27, 27), 출력: (512, 14, 14)
)
self.classifier = nn.Sequential(
nn.Conv2d(512, 4096, 7), # 입력: (512, 14, 14), 출력: (4096, 8, 8)
nn.ReLU(inplace=True),
nn.Dropout2d(),
nn.Conv2d(4096, 4096, 1), # 입력: (4096, 8, 8), 출력: (4096, 8, 8)
nn.ReLU(inplace=True),
nn.Dropout2d(),
nn.Conv2d(4096, self.n_class, 1) # 입력: (4096, 8, 8), 출력: (n_class, 8, 8)
)
self.score_pool4 = nn.Conv2d(512, self.n_class, 1) # 입력: (512, 27, 27), 출력: (n_class, 27, 27)
self.score_pool3 = nn.Conv2d(256, self.n_class, 1) # 입력: (256, 53, 53), 출력: (n_class, 53, 53)
if self.learned_bilinear:
## 전치합성곱층 -> transposed convolution은 학습 가능한 연산임
# 입력 채널 n_class, 출력 채널 n_class, 커널 크기, stride 2, bias
# 다이렉션은 커널 요소 사이의 간격. Astrous sampling에 사용됨.
# 스트라이드가 몇배로 업샘플링하는지 결정함.
## 입출력
# 토치는 기본적으로 배치크기, 채널, 높이, 너비 순
# 출력 높이 = (input_size-1)*stride+kernel_size-2*padding+output_padding
self.upscore2 = nn.ConvTranspose2d(
self.n_class, self.n_class, 4, stride=2, bias=False
) # 입력: (n_class, 8, 8), 출력: (n_class, 18, 18)
self.upscore4 = nn.ConvTranspose2d(
self.n_class, self.n_class, 4, stride=2, bias=False
) # 입력: (n_class, 18, 18), 출력: (n_class, 38, 38)
self.upscore8 = nn.ConvTranspose2d(
self.n_class, self.n_class, 16, stride=8, bias=False
) # 입력: (n_class, 38, 38), 출력: (n_class, 312, 312)
# 모델의 모든 모듈을 순회하면서 nn.ConvTranspose2d 레이어의 가중치를 초기화 하는 역할
for m in self.modules():
if isinstance(m, nn.ConvTranspose2d):
m.weight.data.copy_(
get_upsampling_weight(m.in_channels, m.out_channels, m.kernel_size[0])
)
def forward(self, x):
conv1 = self.conv_block1(x) # 입력: (3, 224, 224), 출력: (64, 211, 211)
conv2 = self.conv_block2(conv1) # 입력: (64, 211, 211), 출력: (128, 106, 106)
conv3 = self.conv_block3(conv2) # 입력: (128, 106, 106), 출력: (256, 53, 53)
conv4 = self.conv_block4(conv3) # 입력: (256, 53, 53), 출력: (512, 27, 27)
conv5 = self.conv_block5(conv4) # 입력: (512, 27, 27), 출력: (512, 14, 14)
score = self.classifier(conv5) # 입력: (512, 14, 14), 출력: (n_class, 8, 8)
if self.learned_bilinear:
upscore2 = self.upscore2(score) # 입력: (n_class, 8, 8), 출력: (n_class, 18, 18)
upsample_index1 = (conv4.size()[2]-upscore2.size()[2])//2+1
score_pool4 = self.score_pool4(conv4)[
:, :, upsample_index1 : upsample_index1 + upscore2.size()[2], upsample_index1 : upsample_index1 + upscore2.size()[3]
] # 입력: (n_class, 27, 27), 중간 출력:(n_class, 27, 27), 출력: (n_class, 18, 18) - 슬라이싱 후 크기 맞춤
upscore_pool4 = self.upscore4(upscore2 + score_pool4) # 입력: (n_class, 18, 18), 출력: (n_class, 38, 38)
upsample_index2 = (conv3.size()[2]-upscore_pool4.size()[2])//2+1
score_pool3c = self.score_pool3(conv3)[
:, :, upsample_index2 :upsample_index2 + upscore_pool4.size()[2], upsample_index2 :upsample_index2 + upscore_pool4.size()[2]
] # 입력: (n_class, 53, 53), 출력: (n_class, 38, 38) - 슬라이싱 후 크기 맞춤
out = self.upscore8(score_pool3c+upscore_pool4) # 입력: (n_class, 38, 38), 출력: (n_class, 312, 312)
upsample_index3 = (out.size()[2]-x.size()[2])//2+1
out = out[
:, :, upsample_index3 : upsample_index3 + x.size()[2], upsample_index3 : upsample_index3 + x.size()[3]
] # 입력: (n_class, 312, 312), 출력: (n_class, 224, 224) - 슬라이싱 후 크기 맞춤
# 1번 인덱스인 class로 계산
out = F.softmax(out, dim=1)
return out.contiguous() # 텐서는 연속적 or 비연속적인데 일분 연산은 연속적인 텐서에만 수행되므로 바꿔줌(슬라이싱 이후 비연속적일 수 있어서..)
# FCN-8s의 모델의 가중치를 사전 훈련된 VGG16 모델의 가중치로 초기화하는 역할
def init_vgg16_params(self, vgg16, copy_fc8=True):
blocks=[
self.conv_block1,
self.conv_block2,
self.conv_block3,
self.conv_block4,
self.conv_block5
]
ranges = [[0,4], [5,9], [10,16], [17,23], [24,29]]
features = list(vgg16.features.children())
# 바이어스의 크기는 (out_channels,) 가중치의 크기는(out_channels, in_channels, kernel_height, kernel_width)
# VGG16의 경우 classifier는 (out_channels, in_channels*kernel_height*kernel_width)라 view로 바꿔줘야 함.
for idx, conv_block in enumerate(blocks):
for l1, l2 in zip(features[ranges[idx][0]: ranges[idx][1]], conv_block):
if isinstance(l1, nn.Conv2d) and isinstance(l2, nn.Conv2d):
assert l1.weight.size() == l2.weight.size()
assert l1.bias.size() == l2. bias.size()
l2.weight.data = l1.weight.data
l2.bias.data = l1.bias.data
for i1, i2 in zip([0, 3], [0, 3]):
l1 = vgg16.classifier[i1]
l2 = self.classifier[i2]
assert l1.weight.size()[0] == l2.weight.size()[0]
l2.weight.data = l1.weight.data.view(l2.weight.size())
l2.bias.data = l1.bias.data.view(l2.bias.size())
n_class = self.classifier[6].weight.size()[0]
if copy_fc8:
l1 = vgg16.classifier[6]
l2 = self.classifier[6]
l2.weight.data = l1.weight.data[:n_class].view(l2.weight.size())
l2.bias.data = l1.bias.data[:n_class]특이한 부분은 첫번재 conv_block에서 첫 conv2d의 padding이 무려 100이라는 점!! 그리고 upsampling이 학습되도록 ConvTranspose2d라는 함수를 사용하였다는 점, pooling layer의 결과와 upsampling layer의 결과를 합치기 위해 cropping하는 부분이 있다는 점, FCN-8s의 모델의 가중치를 사전 훈련된 VGG16 모델의 가중치로 초기화했다는 점이 있겠다.
좀 더 자세히 알아보기 위해 다음의 코드들을 살펴보았는데
# 모델의 모든 모듈을 순회하면서 nn.ConvTranspose2d 레이어의 가중치를 초기화 하는 역할
for m in self.modules():
if isinstance(m, nn.ConvTranspose2d):
m.weight.data.copy_(
get_upsampling_weight(m.in_channels, m.out_channels, m.kernel_size[0])
)def get_upsampling_weight(in_channels, out_channels, kernel_size):
"""Make a 2D bilinear kernel suitable for upsampling"""
# 커널의 중앙 계산
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
# 그리드 생성
# ogrid -> 열린 그리드 생성
og = np.ogrid[:kernel_size, :kernel_size]
# 양선형 보간 필터 생성
filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
# 가중치 텐서 초기화
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype=np.float64)
weight[range(in_channels), range(out_channels), :, :] = filt
# pytorch 텐서로 변환
return torch.from_numpy(weight).float()
nn.ConvTranspose2d layer의 초기 가중치를 양선형 보간법으로 초기화해야 해서 양선형 보간법의 가중치를 넣어주어야 했다. Channel과 kernel의 사이즈에 맞는 가중치를 생성하기 위해 get_upsampling_weight 함수는 위와 같이 정의하여 만들어주었고 동작원리는 다음과 같다.
먼저, og = np.ogrid[:5, :5]는 다음의 배열을 만든다.
[array([[0],
[1],
[2],
[3],
[4]]), array([[0, 1, 2, 3, 4]])]양선형 보간 필터 계산 공식은 다음과 같은데

factor = (kernel_size+1)//2 이고 center는 kernel size가 홀수이면 factor -1, 짝수이면 factor-0.5이다.
이를 통해 filter가 3일때 생성한 filt는 다음과 같다.
kernel_size = 3
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
# 그리드 생성
# ogrid -> 열린 그리드 생성
og = np.ogrid[:kernel_size, :kernel_size]
# 양선형 보간 필터 생성
filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
print(filt)
[[0.25 0.5 0.25]
[0.5 1. 0.5 ]
[0.25 0.5 0.25]]이 필터를 아래 입력 텐서에 적용하면
[[1, 2],
[3, 4]]다음 4개의 연산을 거처


가 출력된다.
다시 코드로 돌아와
# 가중치 텐서 초기화
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype=np.float64)
weight[range(in_channels), range(out_channels), :, :] = filt
# pytorch 텐서로 변환
return torch.from_numpy(weight).float()먼저 weigth를 0으로 초기화 하고 weight[i, j, :, :]은 i=j 일때만 filt로 초기화 한다. 그 후 tensor로 변환해 return
return out.contiguous()다음은 contoguous()에 관한 설명인데 out.contiguous()는 PyTorch 텐서의 메모리 연속성을 보장하기 위해 사용되는 메서드로 이를 이해하려면 먼저 텐서의 메모리 구조와 연속성의 개념을 이해해야 한다.
PyTorch에서 텐서는 메모리에 저장될 때 특정한 순서로 배열된다. 메모리에서 텐서의 요소가 어떻게 배치되는지에 따라 텐서가 연속적(contiguous)일 수도 있고, 비연속적(non-contiguous)일 수도 있는데.
- 연속적 텐서: 모든 요소가 메모리에서 순서대로 저장되어 텐서의 요소들이 메모리에서 끊김 없이 배치된다.
- 비연속적 텐서: 요소들이 메모리에서 순서대로 배치되지 않을 수 있는데 특히, 슬라이싱 연산이나 전치(transpose) 연산 후의 텐서는 비연속적일 수 있다.
연산을 수행하는 동안, PyTorch 텐서는 비연속적일 수 있는데 일부 연산은 연속적 텐서에서만 제대로 동작하므로, 비연속적 텐서를 연속적 텐서로 변환할 필요가 있다. 이때 contiguous() 메서드를 사용하여 텐서를 복사하여 새로운 메모리 블록에 연속적으로 저장된 텐서를 반환한다.
3. 모델, 손실함수 및 옵티마이저 설정
그 다음 모델 instance를 생성하고 가중치 초기화와 손실함수는 CrossEntropyLoss()로, 옵티마이저는 Adam(lr=0.00001)로 설정하였다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
vgg16 = models.vgg16(weights=models.VGG16_Weights.IMAGENET1K_V1)
# vgg16 = models.vgg16(pretrained=True)
fcn_model = FCN8s(n_class=59, learned_bilinear=True)
fcn_model.init_vgg16_params(vgg16)
fcn_model = fcn_model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(fcn_model.parameters(), lr=0.00001)4. 훈련 및 검증 루프
num_epochs = 100
# 모델 훈련 모드
fcn_model.train()
for epoch in range(num_epochs):
# 누적 손실
running_loss=0.0
for images, masks in train_loader:
images = images.to(device)
masks = masks.to(device)
# 이전 배치의 경사도를 초기화 함.
# 각 배치마다 손실함수의 경사도를 계산하고 이를 통해 모델의 파라미터를 업데이트 하는데
# 기본적으로 경사도가 누적되므로 초기화 해야 함.
optimizer.zero_grad()
outputs = fcn_model(images)
# 채널 차원 재거하고 'long'타입으로 변환
# nn.CrossEntropyLoss 쓰려고 채널 차원 제거
# 파이토치에서 long 타입은 64비트 정수를 의미. nn.CrossEntropyLoss에서 long 타입 사용
loss = criterion(outputs, masks.squeeze(1).long())
# 손실에 대한 경사도 계산
loss.backward()
# 모델의 파라미터 업데이트
optimizer.step()
# 현재 배치의 손실 값을 누적 손실에 더합
running_loss += loss.item()
# 에포크가 끝난 후 한 에포크의 손실 값은 배치 크기로 나눠주어 평균 손실 값을 출력
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader)}")
# 검증
fcn_model.eval()
val_loss = 0.0
# 검증 시에는 경사도를 계산하지 않기 위해 메모리 사용량과 연산 속도를 최적화함.
with torch.no_grad():
for images, masks in val_loader:
images = images.to(device)
masks = masks.to(device)
outputs = fcn_model(images)
loss = criterion(outputs, masks.squeeze(1).long())
val_loss += loss.item()
print(f"Validation Loss: {val_loss/len(val_loader)}")
fcn_model.train()
print("훈련 완료")그 다음 단계는 훈련 과정인데 model.train()과 model.eval()의 차이와 nn.CrossEntropyLoss()에 대해 궁금한 부분을 조사해보았다.
먼저, 학습 모드와 평가 모드는 주로 다음과 같은 레이어에서 동작 방식이 달라진다.
- Dropout 레이어:
- 학습 모드 (model.train()): Dropout 레이어는 각 훈련 단계에서 무작위로 일부 뉴런을 비활성화하여 과적합을 방지한다.
- 평가 모드 (model.eval()): Dropout 레이어는 모든 뉴런을 활성화하여 전체 모델을 사용합니다. 따라서 예측을 수행할 때 Dropout이 적용되지않는다.
- Batch Normalization 레이어:
- 학습 모드 (model.train()): Batch Normalization 레이어는 미니배치의 평균과 분산을 사용하여 정규화한다.
- 평가 모드 (model.eval()): Batch Normalization 레이어는 학습 동안 계산된 전체 데이터셋의 이동 평균과 이동 분산을 사용하여 정규화한다.
또한 nn.CrossEntropyLoss는 다음과 같은 형태의 입력을 기대하기 때문에
- outputs: 예측 값, 실수형(float), 형태: [batch_size, num_classes, height, width]
- masks: 타겟 값, 정수형(long), 형태: [batch_size, height, width]
loss = criterion(outputs, masks.squeeze(1).long()) 이런식으로 설정해주었다.
5. 결과 시각화
# 시각화 함수
def visualize(image_tensor, mask_tensor, pred_tensor, mean, std):
image = denormalize(image_tensor, mean, std) # 정규화 역변환 적용
mask = mask_tensor.squeeze(0).cpu().numpy() # Remove the channel dimension
mask = (mask * 255).astype(np.uint8)
pred = pred_tensor.argmax(dim=0).cpu().numpy() # 예측된 클래스
pred = (pred * 255 / pred.max()).astype(np.uint8) # 정규화
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.imshow(image)
plt.title('Image')
plt.axis('off')
plt.subplot(1, 3, 2)
plt.imshow(mask, cmap='gray')
plt.title('Ground Truth')
plt.axis('off')
plt.subplot(1, 3, 3)
plt.imshow(pred, cmap='gray')
plt.title('Predicted Mask')
plt.axis('off')
plt.show()
# 데이터셋에서 배치 하나를 로드하여 시각화
fcn_model.eval()
with torch.no_grad():
for images, masks in val_loader:
images = images.to(device)
masks = masks.to(device)
outputs = fcn_model(images)
# 정규화 역변환에 필요한 mean과 std
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# 첫 번째 이미지와 마스크 시각화
visualize(images[7], masks[7], outputs[7], mean, std)
break # 첫 번째 배치의 여덟 번째 이미지만 시각화이미지 시각화와 비슷한 형태로 진행하였고 결과는 다음과 같다.

6. mean IOU 구하기
def calculate_iou(pred, target, num_classes):
ious = []
# 비교를 위해 일차원으로 변환환
pred = pred.view(-1)
target = target.view(-1)
for cls in range(1, num_classes):
pred_inds = (pred == cls)
target_inds = (target == cls)
intersection = (pred_inds[target_inds]).long().sum().item()
union = pred_inds.long().sum().item() + target_inds.long().sum().item() - intersection
if union == 0:
ious.append(float('nan')) # If there is no ground truth, do not include in IoU
else:
ious.append(float(intersection) / float(union))
if len(ious) != 0 and not np.all(np.isnan(ious)):
return np.nanmean(ious) # Return mean IoU for all classes
else:
return 0
# 전체 데이터셋에 대한 Mean IoU 계산
def mean_iou(model, data_loader, num_classes, device):
model.eval()
iou_list = []
with torch.no_grad():
for images, masks in data_loader:
images = images.to(device)
masks = masks.to(device)
outputs = model(images)
# 예측 클래스 레이블을 얻음
preds = outputs.argmax(dim=1)
for pred, mask in zip(preds, masks.squeeze(1)): # Remove channel dimension from masks
iou = calculate_iou(pred, mask, num_classes)
iou_list.append(iou)
return np.nanmean(iou_list)
# 모델과 데이터 로더 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
num_classes = 59 # 클래스 수 설정
fcn_model.to(device)
# Mean IoU 계산
mean_iou_value = mean_iou(fcn_model, val_loader, num_classes, device)
print(f"Mean IoU: {mean_iou_value}")1번째 차원(인덱스 기준)으로 클래스를 정의한다음 preds = outputs.argmax(dim=1)
for cls in range(1, num_classes):
pred_inds = (pred == cls)
target_inds = (target == cls)
intersection = (pred_inds[target_inds]).long().sum().item()
union = pred_inds.long().sum().item() + target_inds.long().sum().item() - intersection
if union == 0:
ious.append(float('nan')) # If there is no ground truth, do not include in IoU
else:
ious.append(float(intersection) / float(union))
if len(ious) != 0 and not np.all(np.isnan(ious)):
return np.nanmean(ious) # Return mean IoU for all classes
else:
return 0각 class 별로 iou를 구한 다음 평균해주었다.
그 결과 출력은
Mean IoU: 0.10054701150414594원래는 에포크별 mean iou를 출력하는 것이 더 일반적이나 까먹고 코드에 넣지 못해서..
7. 모델 저장
torch.save(fcn_model.state_dict(), 'fcn_model_weight.pt')
## 불러올때
# fcn_model =FCN8s(n_class=59)
# fcn_model.load_state_dict((torch.load('fcn_model_weight.pt')))모델의 가중치를 저장하고 불러올때 쓰는 코드이다.
이렇게 오늘은 FCN8s를 통해 cloth segmentation을 수행해보았다. 물론 github를 불러다 쓰면 쉽게 할 수 있지만 코드를 한줄한줄 짜보는 것도 의미가 있는거 같아 위 코드의 대부분을 수작업으로 짜보았다. 다음은 U-Net 논문 리뷰를 하고 U-Net을 코드로 구현해보는 시간을 가져보겠다.
전체 코드는 다음 깃허브에 올려두었다.