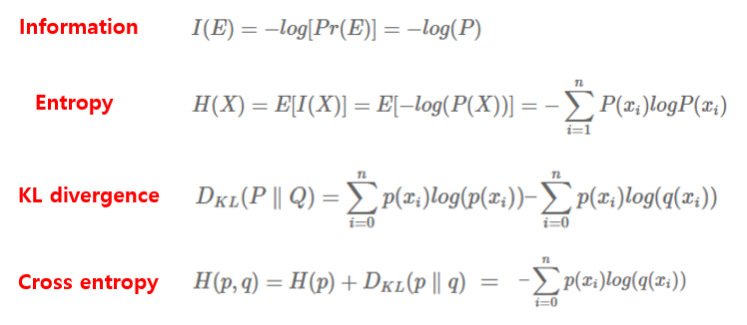여기는 말 그대로 다양한 분야의 잡지식을 기록하고 싶을 때 사용하는 공간입니다. Ctrl+F해서 원하는 지식을 찾을거임.
Time Series
1. EMA(Exponential Moving Average)

Computer Vision
1. 필터와 커널의 차이
- 필터
필터는 신호나 데이터를 처리하는 데 사용하는 장치나 알고맂므을 의미한다. 필터는 다양한 형태로 존재하며, 그 목적에 다라 다르게 설계된다.
- 커널
커널은 주로 행렬 연산을 통해 이미지를 처리하는 데 사용된다. 커널은 필터의 일종으로, 이미지의 특정 픽셀에 적용되어 그 픽셀의 값과 주변 픽셀 값을 조합해 새로운 값을 생성한다.
커널은 항상 matrix의 형태로 표핸되지만 필터는 다양한 형태(물리적인 장치, 소프트웨어 알고리즘)이 가능하다. 필터는 신호 처리 전반에 걸쳐 사용되고 커널은 주로 이미지 처리와 관련된 행렬 연산에 사용된다.
Statistics
1. beta distribution

2. 왜 정규분포는 정규분포를 낳을까?
이 말은 왜 정규분포를 따르는 random variable X와 Y를 더한 Z가 정규분포를 따르는가이다. 수식이 꽤나 길기 때문에 필기로 대체하겠다.



3. KL-Divergence

4. Monte Carlo estimates
확률적 방법을 사용하여 기댓밗, 적분 또는 기타 통계량을 근사하는 방법. 주어진 확률 분포에서 무작위로 샘플을 생성한 다음 그 샘플등을 이용하여 계산하고자 하는 값을 추정한다. 복잡한 수학적 계산을 직접 수행하기 어려운 경우 유용함.
몬테카를로 방법은 다음 단계를 포함합니다:
- 무작위 샘플링: 특정 확률 분포로부터 많은 수의 무작위 샘플을 생성합니다.
- 함수 평가: 각 샘플에 대해 관심 있는 함수를 평가합니다.
- 평균 계산: 함수 값들의 평균을 계산하여 전체 기대값을 추정합니다.
Deep Learning
1. DNN에서 비선형성을 추가하는 것이 중요한 이유
실제 데이터는 종종 매우 복잡하고 비선형적인 패턴을 포함함. 이를 선형 모델로 학습하고 표현하기 어려움. 비선형성이 추가하면 네트워크가 더 복잡해지고 다양한 패턴을 학습할 수 있음.
만약 네트워크에 비선형성을 추가하지 않으면 여러 층을 쌓아도 각 층이 단순히 선형 변환을 수행하게 되어 전체 모델은 결국 하나의 선형 변환으로 축약됨. -> 층을 추가시키는 것이 효과가 없음.
즉, 실제 데이터를 잘 표현하고 모델의 표현력을 증가시키기 위해서 비선형성을 DNN에 추가시켜야함.
2. Cross entropy loss
Cross entropy loss는 머신 러닝의 분류에서 모델이 얼마나 잘 수행하는지 측정하기 위해 사용되는 지표로 multi-class classification에 사용된다.(Binary classification에서는 Log loss를 사용!)
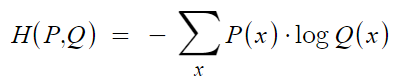
식은 위와 같고 P(x)는 실제 분포, Q(x)는 모델이 예측한 분포이다. KL-Divergence와 Entropy를 더하면 위 식이 나온다고 한다.